

先做个广告:如需代注册ChatGPT或充值 GPT5会员(plus),请添加站长微信:gptchongzhi
今天OpenAI重磅发布了他们的视频生成大模型Sora,该模型可支持长达一分钟的高质量视频内容的生成,又着实又令人震惊了一把。Sora除了能够根据直接根据提示词成一分钟的视频,还支持:
 推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
1)通过提示词让图片动起来

一只戴着贝雷帽和黑色高领毛衣的柴犬
A Shiba Inu dog wearing a beret and black turtleneck
2)在时间维度上向前和向后扩展生成的视频
3)视频到视频的编辑,通过给定一个视频,然后通过给定一定的提示词就可以实现视频内容的编辑,有点类似我上一篇文章提到的ReplaceAnything3D
将设置更改为茂密的丛林
4)视频连接融合,这个有点类似视频差值融合,输入两个完全不同主题的视频,视频可以生成无缝的过渡

但是让我真正感兴趣的是OpenAI产品主页上关于Sora的介绍:
“We’re teaching AI to understand and simulate the physical world in motion, with the goal of training models that help people solve problems that require real-world interaction.
(我们正在教人工智能理解和模拟运动中的物理世界,目标是训练模型来帮助人们解决需要现实世界交互的问题)"
以及OpenAI后续发布的技术报告《Video generation models as world simulators》(视频生成模型用作世界模拟器)。
在技术报告的摘要以及结尾部分,OpenAI都在强调针对视频数据的大模型训练的探索,让他们相信大规模视频生成模型是构建物理世界通用模拟器的一条有前途的路径。
“We believe the capabilities Sora has today demonstrate that continued scaling of video models is a promising path towards the development of capable simulators of the physical and digital world, and the objects, animals and people that live within them。”
所以OpenAI在对Sora的定位其实是想把它做成一个「物理世界通用的模拟器」。
这句话听着非常耳熟,因为无论是GIS还是数字孪生其实都在追求物理世界的建模表达,只是过去的探索成果只是停留在了数据融合以及可视化层面,但是物理世界的通用模拟并没有达成,还是停留在一层皮的阶段。

过去一段时间,我们也在项目上也尝试在现有的可视化模型基础上使用一些行业的模型进去,但是通常遇到一些困难:
1、缺乏模型或者模型的使用效果不太好,比如在网格化的应用中,目前针对网格的划分主要还是依靠客户的经验来进行网格化分,其实分析下来这个部分完全可以依靠一些数据驱动的分析模拟模型进行驱动,但是目前匹配的算法比较少,但是对于做项目类型的公司又很难直接投入资源进行相应的模型算法的研发,更多的还是希望能够有一些开源或者是付费的工具直接进行使用。
2、专业模型门槛比较高,应用代价比较大,目前行业中比较专业的行业模拟仿真模型还是掌握在一些专业的团队手中,比如水利行业的模型,这些模型的应用都需要专业的人员来设计以及调试,很难做到开箱即用,正是由于这种专业化,也导致了这些模型的应用成本很高。
其实物理世界模拟器,不仅仅在数字孪生领域是个难点,其实在AI领域世界模型也是个难点,Meta的首席人工智能科学家Yann Lecun(杨立昆)在他的论文《A Path Towards Autonomous Machine Intelligence 》中就提到:
“可以说,为世界模型设计架构和训练范式是未来几十年人工智能真正取得进展的主要障碍。”
为什么在人工智能领域也要做世界模型或者是世界模拟器呢?
因为Yann Lecun认为目前单纯根据概率生成自回归的大语言模型很肤浅,缺乏对世界的理解,从本质上根本解决不了幻觉、错误的问题,并给出了他认为的正确答案——世界模型,并且给出了他的通用人工智能的理想架构。
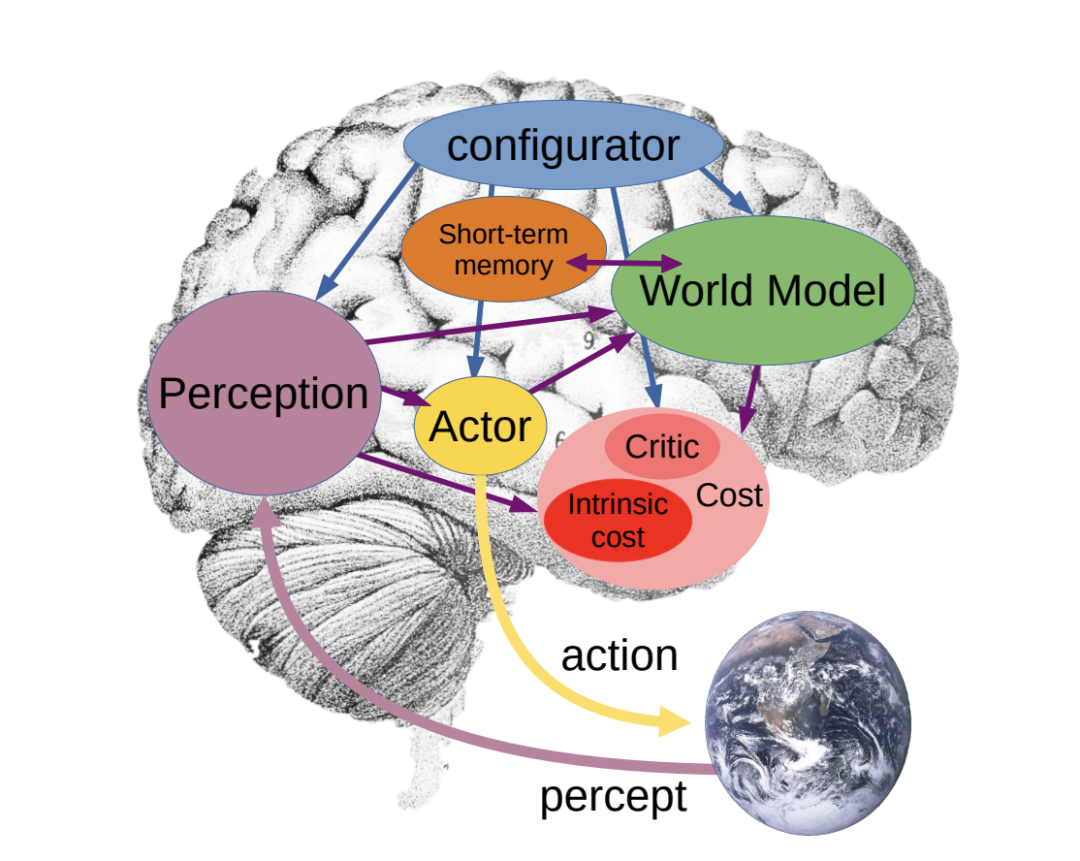
在这个架构中,「世界模型」模块构成了最复杂的部分,它有两方面的作用:
第一、估计感知不提供的关于世界状态的缺失信息;
第二、预测世界的合理未来状态。
世界模型可以预测世界的自然演化,或者可以预测由actor模块提出的一系列动作产生的未来世界状态。
世界模型可以预测多个似是而非的世界状态,由代表世界状态不确定性的潜在变量参数化。
世界模型是世界特定方面的一种“模拟器”。世界状态的哪些方面是相关的,取决于手头的任务。预测是在包含与手头任务相关的信息的抽象表示空间中执行的。理想情况下,世界模型将在多个抽象层次上操纵世界状态的表示,使其能够在多个时间尺度上进行预测。
而让OpenAI觉得Sora这种视频生成模型可以成为世界模拟器的原因在于,OpenAI发现,视频模型在大规模训练的时候出现了一些「涌现」的能力,这些能力使得Sora能够模拟现实世界中人、动物和环境,这也让OpenAI认为视频模型已经具备了理解世界规律的能力。
比如Sora可以生成带有动态相机运动的视频,随着摄像机的移动和旋转,人和场景元素在3D空间中保持了一致移动的效果
Sora还可以用简单的模式模拟世界中的一些动作,比如画家可以在画布上留下新的笔触,一个人可以吃汉堡并留下咬痕。
Sora还可以模拟人工过程,比如视频游戏等。
但是目前也发现了Sora的一些局限性,比如它不能准确地模拟许多基本相互作用的物理过程,例如玻璃破碎,但是这些问题未来应该都是可以得到解决的。
目前从视频生成的角度去看Sora可能大家觉得这个工具主要是针对一些视频创作者是有直接的应用价值的,但是如果从世界模拟器的角度去看,目前的AI大模型已经逐渐开始具备理解物理世界的能力,假设未来它可以进一步的理解地理空间,这样我们就可以通过地图以及相应的一些业务要求,比如「基于当前的区域生成一个安保方案」,「基于当前的河道以及水文数据生成未来三天洪水的演进过程」等等。
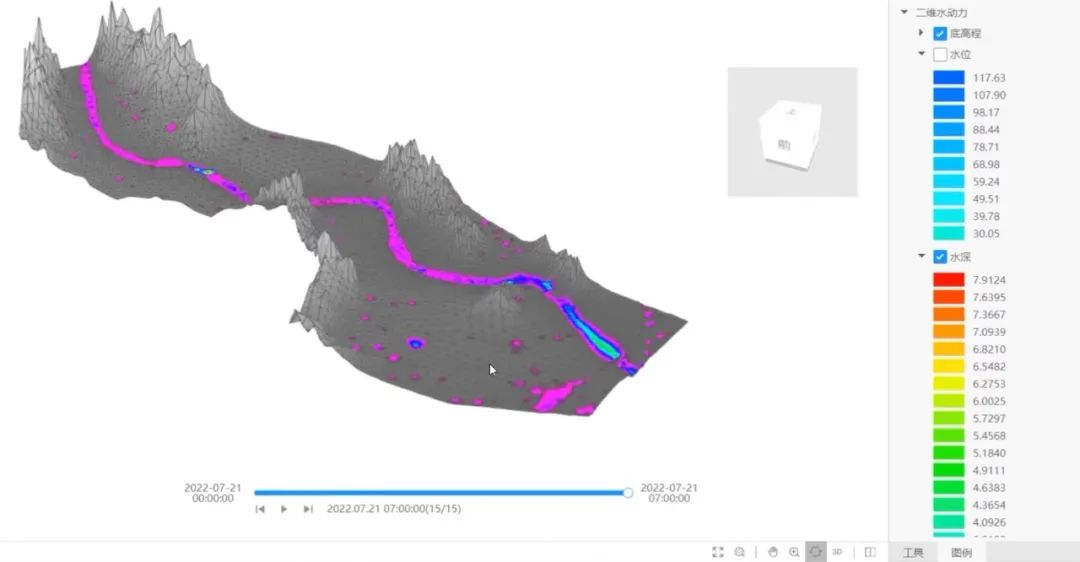
这些看似很难很专业的问题,未来可能得益于世界模拟器的突破这些问题的解决都开始变得更加简单,而且这也是当前数字孪生需要解决的问题,在这一点上数字孪生和AI大模型也会进一步的走向融合。
代充值")





网友评论