

先做个广告:如需代注册ChatGPT或充值 GPT5会员(plus),请添加站长微信:gptchongzhi
OpenAI自己的 AI 问答搜索引擎曝光
似乎叫 SearchGPT,支持 :
 推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
通过聊天问答形式搜索全网任何内容
支持图像搜索
小部件(天气、计算器、体育、金融和时区等)
支持交互式的后续追问
输入网址总结任意网页内容
openai已与 @FT ChatGPT 合作增强新闻内容
从ChatGPT代码看到快要支持连接外部知识库了,包括Google Drive, 微软OneDrive, Notion
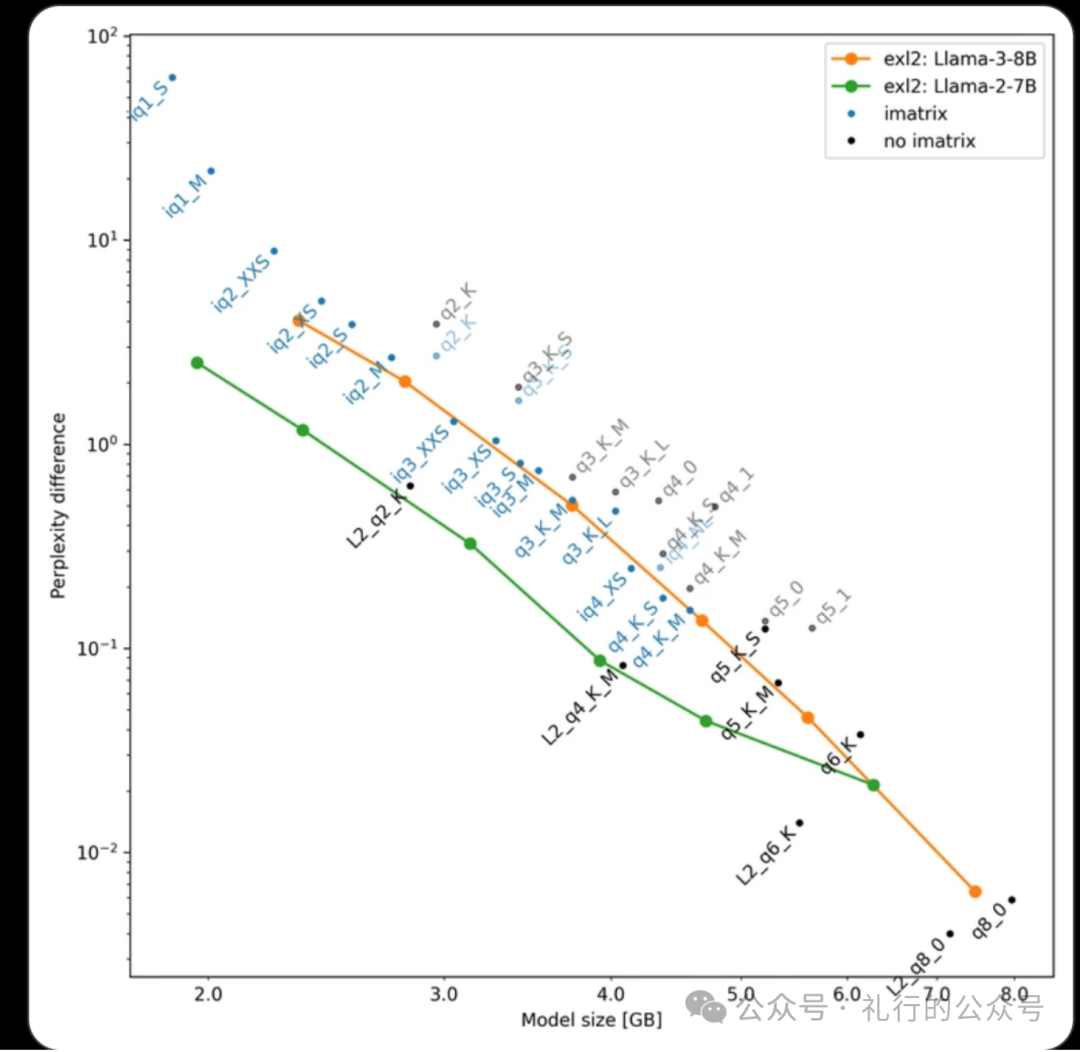
LLama3 量化后性能逐渐低于 LLama2
Llama 3 在量化时比 Llama 2 性能下降的得更多。
可能是因为 Llama 3 在创纪录的 15T 数据上训练,捕获了极其细微的数据关系,甚至充分利用了 BF16 精度中最细微的小数点。
使其对量化退化更敏感。
源:https://reddit.com/r/LocalLLaMA/comments/1cfbadc/result_llama_3_exl2_quant_quality_compared_to/
中文 Phi-3 模型开源
Phi-3-mini 发布并开源一周后,HuggingFace 目前仅有一个中文微调模型
shareAI/Phi-3-mini-128k-instruct-Chinese
基于 Phi-3-mini-128k-instruct 模型,使用 ShareGPT-Chinese-English-90k 数据微调
Phi-3-mini-128k-instruct-Chinese: https://huggingface.co/shareAI/Phi-3-mini-128k-instruct-Chinese
DataSet:
https://huggingface.co/datasets/shareAI/ShareGPT-Chinese-English-90k
LLM结构化的数据 streaming
如果你既想在 LLM 中获得结构化的数据返回,又想要有 streaming 的速度,可以考虑下 best-effort-json-parser 这个库,虽然原理都是大力出奇迹,但是肯定比自己写要靠谱
这里有一篇 step by step 的文章:https://mikeborozdin.com/post/json-streaming-from-openai
免费的 LLM playground 平台
想测试最新的开源模型,而不希望自己去部署。现在市面上有如下几个免费使用的playground,推荐。
聊天模型:
https://sdk.vercel.ai/
https://groq.com
https://huggingface.co/chat/
基础模型:
https://playground.ai.cloudflare.com
https://console.groq.com/playground
Qwen1.5-110B 开源
现在Qwen1.5-110B的权重出来了!目前只有基础和聊天模型、AWQ 和 GGUF 量化模型即将发布!
博客:https://qwenlm.github.io/blog/qwen1.5-110b
底座:https://huggingface.co/Qwen/Qwen1.5-110B
聊天:https://huggingface.co/Qwen/Qwen1.5-110B-Chat
与Llama-3-70B相比如何?对于初学者来说,Qwen1.5-110B至少有几个独特的功能:
32K 令牌的上下文长度。多语言支持,包括英语、中文、法语、西班牙语、日语、韩语、越南语等。该模型仍然基于与 Qwen1.5 相同的架构,并且是密集模型而不是 MoE。它像Qwen1.5-32B一样支持GQA。
我们训练了多少数据?从本质上讲,它是使用非常相似的预训练和训练后配方构建的,因此它仍然远未得到充分的预训练。
我们发现它在基本语言模型的基准测试中表现良好,我们对基础模型的质量充满信心。对于聊天模型,我们在 MT-Bench 中具有相当的性能,但我们也发现了编码、数学、逻辑推理方面的一些缺点。老实说,我们需要您的测试和反馈来帮助我们更好地了解模型的功能和局限性。
摩根大通人工智能研究部推出 FlowMind 工具
可自动化金融工作流程
FlowMind 利用GPT自动生成工作流程,在金融行业,处理诸如信货审批、风险评估、合规监测等任务时,自动化这些流程,提高效率并减少人为错误。
由于FlowMind常用于处理敏感数据(特别是在金融行业),其架构特别强调数据安全和隐私保护:
LLM在生成和执行工作流时,并不直接接触或处理任何敏感数据或专有代码。所有操作都通过抽象的API描述进行,这些描述只提供足够的信息以供LLM理解和执行任务,而不暴露底层数据细节。
传统自动化工具往往缺乏用户参与和个性化配置的空间。FlowMind通过集成用户反馈机制,允许用户直接参与工作流的优化和定制,使最终的自动化解决方案更符合用户的具体需求。
Prompt技巧:使用三元组结构提取文章的核心信息
大模型因为学习了很多知识图谱的三元组
所以在提取信息的时候,如果用三元组来提取,效果会比直接提取要好很多。
可能适合在一些搜索和思维导图的场景里使用。
提取三元组后,可以构建知识图谱,kimi原生已经支持了知识图谱。
关于三元组的一些科普:https://zhuanlan.zhihu.com/p/237452918
Meta 的论文:用AI快速生成能骗过语言模型的对话
它先用一个语言模型(AdvPrompter)来生成诱导对话,然后通过优化使得生成的对话能骗过目标语言模型。
这个训练过程交替进行两个步骤:
1)用优化过的AdvPrompter预测生成高质量的对抗性对话;
2)用生成的对话数据微调AdvPrompter。
训练好的AdvPrompter可以快速生成隐蔽但不改变原意的对话,从而诱骗目标语言模型给出有害的回复。
代充值")
本文链接:https://shikelang.cc/post/1230.html
股票量化策略安卓版chatgpt怎么下载chatgpt 国内用户怎么玩使用chatgpt提问最多的问题GPT使用技巧ChatGPT Plus充值chatGPT 写毕业论文chatgpt plus如何付费蓝凌MK阿里云大规模降价





网友评论