

先做个广告:如需代注册ChatGPT或充值 GPT5会员(plus),请添加站长微信:gptchongzhi
2024年5月13日OpenAI发布了最新的大模型GPT-4o。名称中的"o"代表"Omni"(全部)。
 推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
在GPT-4o之前,用户可以使用语音模式与ChatGPT对话,但这是由3个独立的模型驱动的。GPT-4o将这些功能整合为一个模型,使用同一模型就可以统一处理文本、视觉和语音。最关键的是GPT-4o的价格是GTP-4 Turbo的一半!!
本文将和大家一起通过实例来了解一下如何使用GPT-4o API处理文本、图像和视频。
1
准备
首先,安装 OpenAI SDK for Python。

然后,在OpenAI官方网站登录自己的账号,并生成一个API密钥。
https://platform.openai.com/api-keys
推荐将 API 密钥设置为系统的环境变量,应用于所有项目。
2
文本处理
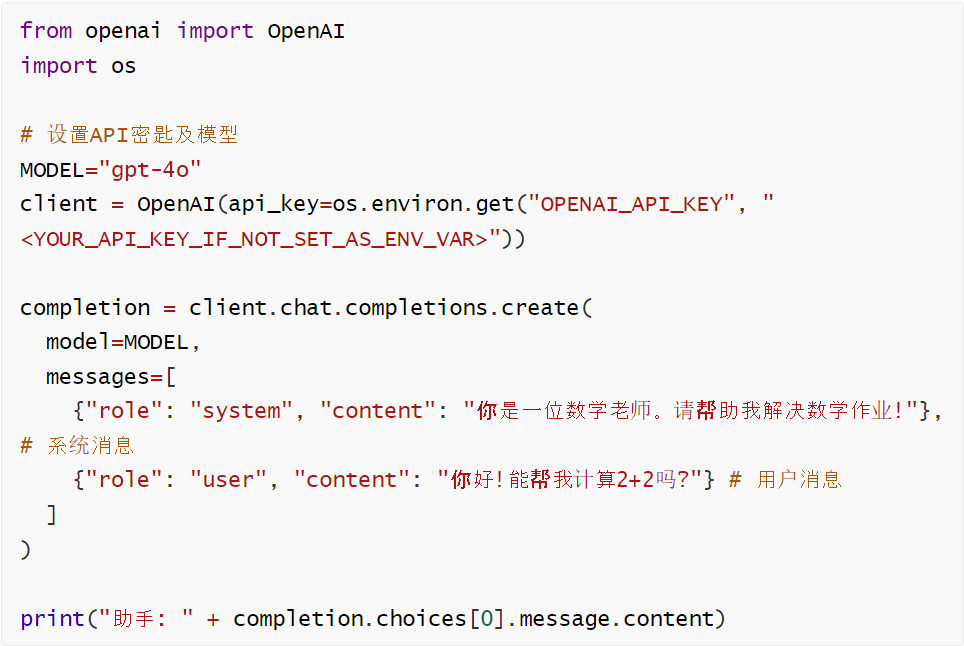

执行结果:
助手: 你好!当然可以!2 加 2 等于 4。

3
图像处理
GPT-4o能够直接处理图像,并基于图像做出响应,图像可以通过以下两种形式提供:
Base64编码
URL链接
我们来用下面的图片,尝试以Base64格式和URL链接的形式将此图像发送至API并计算出三角形的面积。
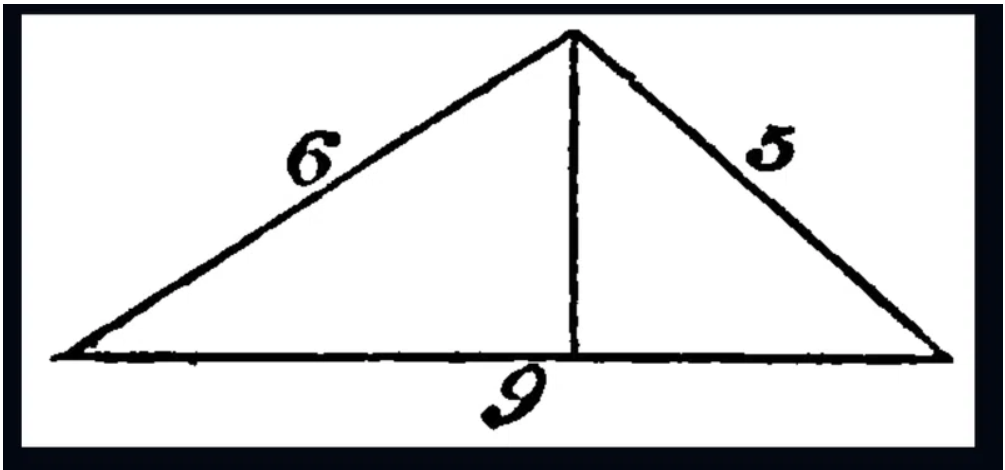
→Base64图像处理


→URL图像处理

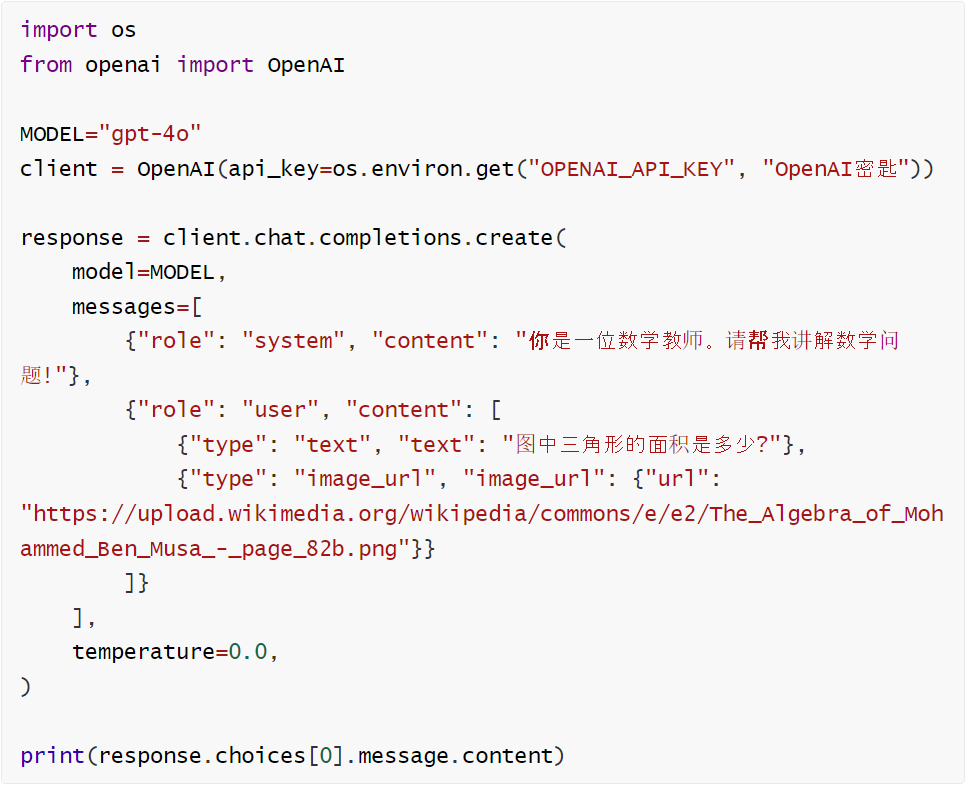
输出会分别展示助手对Base64编码图像和URL链接图像的响应。

执行结果:

4
视频处理
目前我们无法通过API直接将视频发送到API,但GPT-4o能够通过对视频帧进行采样并以图像形式提供,从而理解视频内容。截至2024年5月,GPT-4o API尚不支持语音输入,但可使用Whisper处理音频。

视频分割
视频处理需要使用两个Python包:opencv-python和moviepy。它们需要ffmpeg的支持,因此请先行安装。根据您的操作系统,需要执行brew install ffmpeg或sudo apt install ffmpeg。

我们使用OpenAI DevDay Keynote Recap视频,可以通过下面的URL查看。我们把该视频下载保存到本地。
https://www.youtube.com/watch?v=h02ti0Bl6zk
视频将被分解为帧(画面)和音频两个部分进行处理。

视频帧和音频都已就绪,我们将对模型运行一些不同的测试,生成视频总结,并比较使用不同模态时的结果。

视觉总结
视觉总结是通过仅向模型发送视频帧来生成的。仅依赖画面,模型能捕捉视觉方面的内容,但会错过讲者所阐述的细节。


执行结果
在这段视频中,OpenAI举办了一个名为“OpenAI DevDay”的开发者活动。视频展示了活动的开场、会场布置以及演讲内容。以下是视频的主要内容:
1.活动开场:
△视频以“OpenAI DevDay”的标题开场,随后展示了活动的场地和布置。
2.主题演讲回顾:
△演讲者在舞台上介绍了OpenAI的最新进展和产品。
△重点介绍了GPT-4 Turbo的发布及其功能,包括更长的上下文长度、更高的控制能力和更好的知识库。
△演讲中还提到了JSON模式的开启和函数调用的改进。
3.产品发布:
△演讲者介绍了DALL-E 3、GPT-4 Turbo with Vision和TTS(文本转语音)等新产品。
△还展示了自定义模型的功能,允许用户根据自己的需求定制模型。
4.功能演示:
△演讲者展示了如何使用自然语言进行构建,并介绍了API的使用。
△还展示了线程、检索、代码解释器和函数调用等功能。
5.总结和结束:
△演讲者总结了活动的主要内容,并感谢了参与者。
△视频以“OpenAI DevDay”的标志结束。
视频通过展示OpenAI的最新技术和产品,向开发者们传达了公司的最新动态和未来发展方向。

如预期,模型能在较高层面上捕捉视频的视觉方面,但遗漏了讲话中提供的细节。

音频总结
音频总结是通过向模型发送音频的文字记录来生成的。仅使用音频的情况下,模型会偏向于音频内容,忽略了演示文稿和视觉上提供的上下文。目前GPT-4o无法接收语音输入,因此我们使用Whisper-1模型处理音频。


执行结果
欢迎来到我们首次举办的OpenAI开发者日。今天,我们发布了一个新模型——GPT-4 Turbo。以下是一些关键亮点:
GPT-4 Turbo
上下文支持:支持最多128,000个token的上下文。
JSON模式:确保模型响应有效的JSON格式。
多功能调用:可以同时调用多个函数,并且更好地遵循指令。
知识检索:可以从外部文档或数据库中引入知识。
知识更新:GPT-4 Turbo的知识更新至2023年4月,并将持续改进。
API集成:Dolly 3、GPT-4 Turbo with Vision和新的文本转语音模型今天都将进入API。
自定义模型
新计划:推出了一个名为Custom Models的新计划。
合作:研究人员将与公司密切合作,帮助他们使用我们的工具创建适合其特定用例的定制模型。
速率限制
提高速率限制:我们将所有已建立的GPT-4客户的每分钟token数量翻倍。
费用降低:GPT-4 Turbo的提示token费用是GPT-4的三分之一,完成token费用是其二分之一。
GPTs
定制版本:GPTs是为特定目的定制的Chat GPT版本。
无代码编程:无需编程知识,通过对话即可编程GPT。
共享与隐私:可以创建私人GPT,也可以通过链接公开分享,或在Chat GPT Enterprise中为公司创建专用GPT。
GPT商店:本月晚些时候将推出GPT商店。
Assistance API
持久线程:包括持久线程,内置检索,代码解释器和沙盒环境中的Python解释器。
改进的功能调用:改进了功能调用。
展望未来
随着智能技术的广泛集成,我们将拥有随时可用的“超级能力”。我们期待看到大家利用这项技术所做的创新,并共同构建新的未来。感谢大家的参与和支持,期待明年再见。
感谢大家今天的到来。

音频总结偏向于讲话内容,结构比视觉总结差。

音频+视觉总结
通过同时提供音频和视觉输入,生成的总结能够从两个模态中获取信息,因此是最全面的。


执行结果
在首次举办的OpenAI开发者日活动中,OpenAI宣布了一系列新产品和功能:
1.GPT-4 Turbo:新模型GPT-4 Turbo支持多达128,000个上下文标记,并且具有更好的指令遵循能力。它还引入了JSON模式,确保模型响应有效的JSON格式。
2.功能调用:现在可以同时调用多个函数,并且模型在遵循指令方面表现更好。
3.检索功能:平台上推出了检索功能,可以将外部文档或数据库中的知识引入到构建的应用中。
4.知识更新:GPT-4 Turbo的知识更新至2023年4月,并将继续改进。
5.新API功能:DALL-E 3、带视觉功能的GPT-4 Turbo和新的文本转语音模型都将进入API。
6.定制模型:推出了定制模型计划,OpenAI的研究人员将与公司密切合作,帮助他们使用OpenAI的工具创建适合其特定用例的定制模型。
7.更高的速率限制:为所有已建立的GPT-4客户将每分钟的标记数翻倍,并可以在API账户设置中直接请求更改速率限制和配额。
8.GPT-4 Turbo定价:GPT-4 Turbo的价格比GPT-4便宜得多,提示标记便宜3倍,完成标记便宜2倍。
9.GPTs:推出了GPTs,这是为特定目的定制的ChatGPT版本,结合了指令、扩展知识和操作,可以在许多上下文中更好地工作,并提供更好的控制。用户可以通过对话来编程GPT,创建私人GPT,或通过链接公开分享,企业用户还可以为公司创建专用GPT。
10.GPT商店:将在本月晚些时候推出GPT商店。
11.API改进:助理API包括持久线程、内置检索、代码解释器(在沙箱环境中运行的Python解释器)和改进的函数调用。
OpenAI表示,随着智能技术的广泛集成,每个人都将拥有按需的超级能力,并期待看到大家利用这些技术所做的创新和共同构建的新未来。

将视觉和音频相结合,可以生成对视频内容的详细全面总结。
5
结论
集成诸如文字、音频、视觉等多种输入模态,模型在各种任务上的性能都将大幅改善。
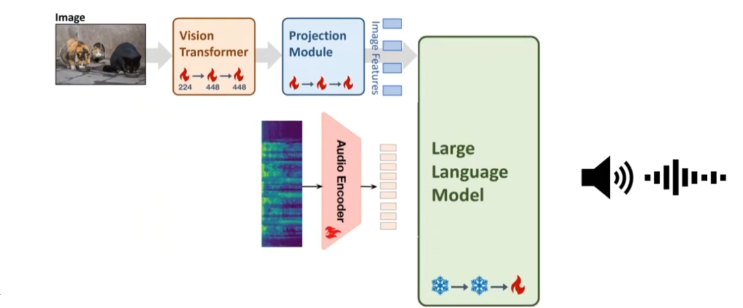
这种多模态的方法使得理解与交互变得更加全面,更接近人类处理信息的方式。目前,GPT-4o API支持文本和图像输入,语音功能将于不久后添加。
代充值")
本文链接:https://shikelang.cc/post/1274.html
与chatgpt聊天要付费吗chatgpt4.0chatgpt app图标chatgpt4使用教程chatgpt注册用什么手机号chatgpt字数限制国内有哪些类似chatgpt的软件登录chatgpt 429chatgpt提问的问题GPT使用技巧





网友评论