

先做个广告:如需代注册ChatGPT或充值 GPT5会员(plus),请添加站长微信:gptchongzhi
“草莓”推理AI模型,在很多文章的报道来看,它前身应该是来自于Q*模型。在2023年11月左右,有几个研究人员发文给董事会一封警告信,信里面写的内容表示:Q*模型发展得过于强大,强大到可以威胁人类得进步。
 推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top

那么Q*模型到底是什么东西?目前只知道它有很强的推理能力,其在数学问题上可以解决很多目前大语言模型解决不了的问题。
从网上来看,“草莓”模型的前身Q*模型的架构存在两种猜想,下面来简单介绍一下
1
Q*模型是Q-learning和A*算法的结合这是目前网上最流行的一种猜测方法。从名字可以看出Q*模型可能分别表示Q-learning和A*算法的结合。
Q-learning是强化学习中的一个概念,它属于无模型下的一个基于价值的算法。主要是基于环境中给定的条件和状态,学习动作action和价值value。
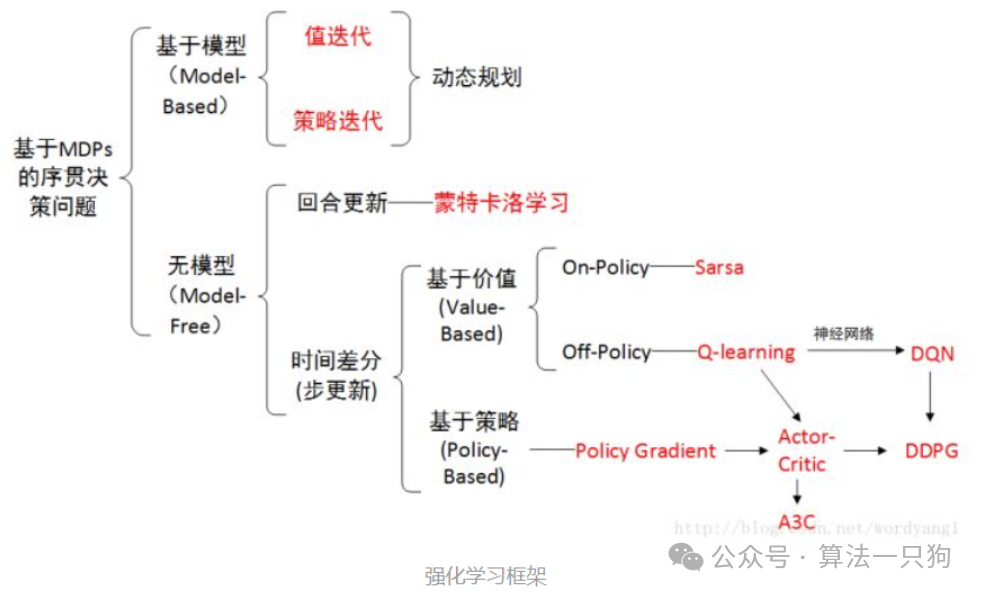
传统的Q-learning需要保存一个Q表来进行更新。其最终目标是找到一个最优策略,定义在每个状态下采取的最佳动作,从而随着时间的推移最大化累积奖励(reward)。
而值得令人注意的是,OpenAI在2016年的一个演讲中曾经提到过这个概念,并引入 Q* 到优化策略中:

另一种算法是A*算法,这种算法是用在求解最短路径中的有效直接搜索方法。相信学过算法结构的人对于Dijkstra 算法不陌生,而A*算法不像别的算法,它是有“脑子”的。它使用到了启发式(Heuristics)函数来帮助搜索更快收敛到最短路径,非常高效。
而对于然而,Q-learning 算法和A*算法到底是不是真的用在了“草莓”推理AI模型中呢?这些常规算法对于Q*模型有用吗?可能要等公布的那天才知道
2
过程监督解决数学问题第二种推测涉及到OpenAI于上一年5月份发布的一项技术,该技术通过“过程监督”而非“结果监督”来解决数学问题。
OpenAI通过对每个正确的推理步骤进行奖励(“过程监督”)来提高解决数学问题的水平,而不是像之前一样只是简单地奖励最终的正确答案(“结果监督”)。
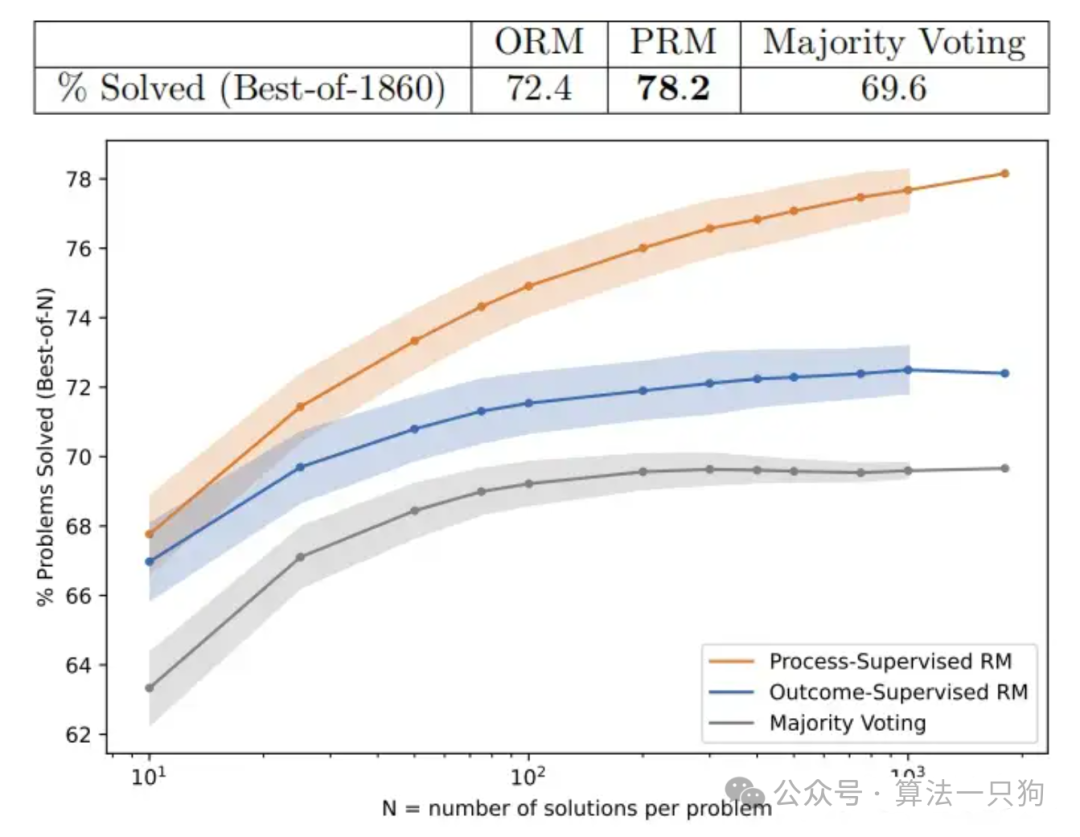
OpenAI使用MATH测试集里面的问题来评估“过程监督”和“结果监督”奖励模型,并为每个问题生成了许多解答方案,然后选择每个奖励模型排名最高的解答方案。
上图展示了一个函数,即每个奖励模型选择的解答方案数量(number of samples)与选择的解答方案最终能够达到正确结果的百分比(% Problems Solved (Best-of-N))之间的关系。
除了提高与结果监督相关的性能外,过程监督还有一个重要的对齐好处:它直接训练模型以产生人类认可的思维链。

从之前OpenAI发布的论文来看,使用过程监督有以下优点:
过程监督更有效,从具有挑战性的 MATH 数据集的一个子集中解决了 78% 的问题。
主动学习提高了流程监督的有效性,数据效率提升了2.6倍。
所以“草莓”AI模型不排除也使用了这种方法,从而提高了其数学推理能力。
3
总结不过这并不是OpenAI的一次画饼了,每次都说快要发布新产品,但是可能也是一次PPT讲故事。毕竟互联网还是有记忆的:
2024年2月推出了Sora文生视频,到现在了,还没有开放
GPT-4o的语音功能,也在一直测试中,没有大范围发布出来
心心念念的GPT-5还没有消息
前不久还画饼了一个SearchGPT吗,说是要打破谷歌搜索现在的垄断地位
所以也不怪大家现在都觉得这个功能可能也要很久才会正式上线。要知道其他家的大模型已经赶上来了,GPT-4已经是上一年的模型了,OpenAI还是要加把劲,不然到时候大部分用户可能就会转用其他的AI产品,毕竟每个月的20美元并不便宜
代充值")





网友评论