

先做个广告:如需代注册ChatGPT或充值 GPT5会员(plus),请添加站长微信:gptchongzhi
 推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
#01
前言-OpenAI最强模型来了!
OpenAI今年憋的最大招终于出来了,就在9月13日凌晨1点,在无任何预告的情况下“草莓”模型重磅发布。
在多个基准测试中力压群雄,直接超过了人类博士水平!但其实正式版名称不叫草莓,草莓只是内部的一个代号。
他们的正式名字,叫:OpenAI o1
这次o1模型的问世,甚至让OpenAI破天荒地抛弃了以往GPT系列的命名,开创了全新的"o系列"。
实力!简直强无敌!
作为OpenAI开创的新系列模型,o1究竟强在哪?
它在竞赛编程问题(Codeforces)中排名前89%;在美国奥数竞赛预选赛(AIME),位列前500名学生之列。
最重要的是,它在物理、生物、化学问题的基准测试中(GPQA),超过了人类博士水平。
#02
轻松
干翻物理博士
超越奥赛冠军
编程能力8倍秒杀GPT-4o
OpenAI o1模型被训练得更像人类一样,加注重思考时间,在做出回答前会先进行深入的思考,生成一条长而复杂的内部推理链。
目前,作为早期预览版本,OpenAI o1仅支持文本对话功能,尚未具备多模态功能,如浏览网页、上传文件或图片。
在性能表现方面,OpenAI o1在物理、化学和生物学等领域的基准测试中表现堪比博士生,在数学和编程任务上表现更为出色。
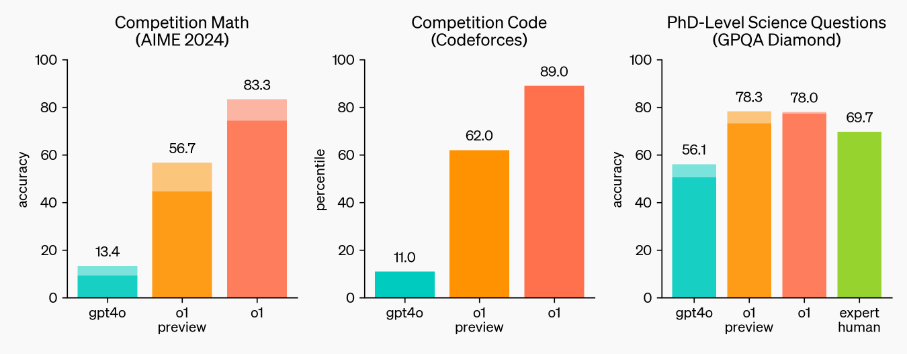
▲OpenAI o1在数学、编程上的测评基准
在推理常用的MATH、GSM8K等基准测试上,o1和最近很多的前沿模型已经达到了饱和表现,很难有区分度,因此OpenAI主要选择了AIME评估模型的数学和推理能力,以及其他人类考试和基准测试。
AIME旨在挑战美国最优秀的高中学生的数学能力,在2024年的AIME考试中,GPT-4o平均仅解决了12%(1.8/15)的题目。
o1的提升相当显著,平均解决了74%(11.1/15)的题目,在64个样本中进行多数投票时达到了83%(12.5/15)。
如果使用打分函数并重新排序1000个样本,准确率甚至达到了93%(13.9/15)。
13.9的得分,意味着o1的水平达到了全国前500名学生之列,并超过了美国数学奥赛的入围分数。
在Codeforces、GPQA Diamond这种有挑战性的任务上,o1远远超过了GPT-4o。
▲o1预览版与GPT-4o性能对比
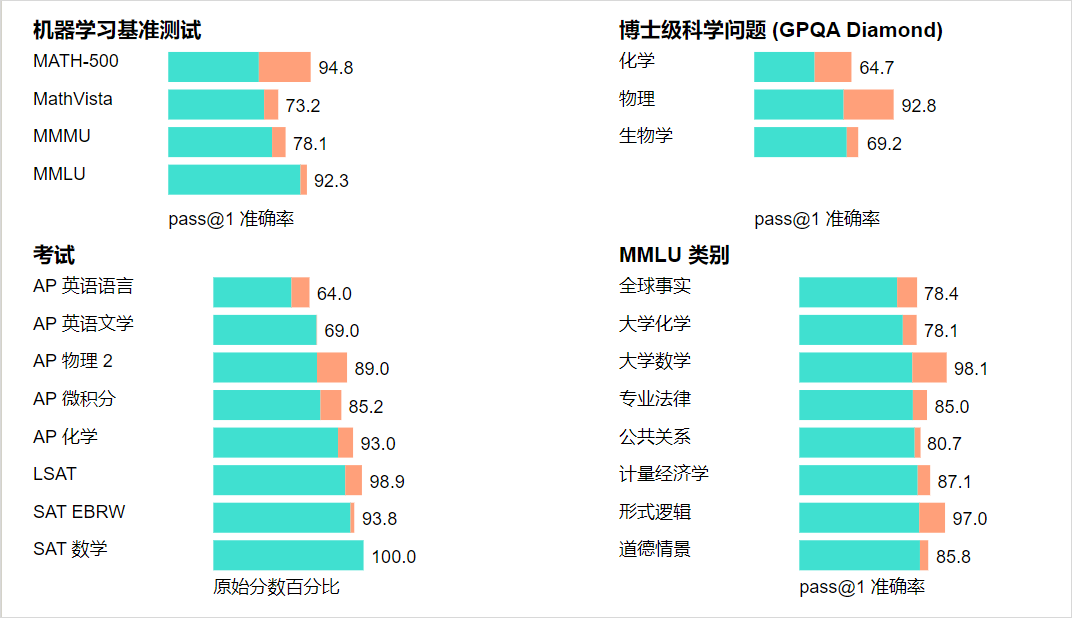
GPQA Diamond测试的是化学、物理和生物学领域的专业知识。
为了将模型与人类进行比较,团队招募了拥有博士学位的专家来回答其中的问题。
结果是,o1的表现(78.0)超过了这些人类专家(69.7),成为第一个在此基准测试中超越人类的模型。
然而,这个结果并不意味着o1在所有方面都强于拥有博士学位的人类,仅仅表明它能更熟练地解决一些相应水平的问题。
此外,在MATH、MMLU、MathVista等基准测试中,o1也刷新了SOTA。启用视觉感知能力后,o1在MMMU上取得了78.1%的成绩,成为第一个能与人类专家竞争的模型,在57个MMLU子类别中,有54个类别超过了GPT-4o。
从数据结果来看,可以说o1是势如破竹,完全可以与人类专家一决高下。
特别是在测试化学、物理和生物学专业知识的基准GPQA-diamond上,o1的表现全面超过了人类博士专家,这也是有史以来,第一个获得此成就的模型。
而整个模型之所以达到如此成就,基石就是Self-play RL。
人类的有两种思考方式——出自《思考,快与慢》
第一种是快思考(系统1),特点是快速、自动、直觉性、无意识,举几个例子:
看到一个表情就知道对方心情如何。
1+1=2 1+2=3 这样简单不需要怎么思考的计算。
开车时遇到危险情况立即踩刹车。
这些就是快思考,也就是传统的大模型,死记硬背后学得的快速反应的能力。
第二种是慢思考(系统2),特点是缓慢、需要努力、逻辑性、有意识,举几个例子:
解决一道复杂的数学题
填写重要的商务合同
需要做出足以改变人生的重要决定时刻
这就是慢思考,而o1终于踏出了坚实的一步,拥有了人类慢思考的特质,在回答前,会反复的思考、拆解、理解、推理,然后给出最终答案。
这些增强的推理能力在处理科学、编码、数学及类似领域的复杂问题时绝对极度有用。
例如o1可以被医疗研究人员用来注释细胞测序数据,被物理学家用来生成量子光学所需的复杂数学公式,以及被各个领域的开发人员用来构建和执行多步骤工作流等等。
#03
迷你版
速度提升3~5倍
成本仅为标准版的1/5
目前,o1模型已经逐步向所有ChatGPT Plus和Team用户开放,也就是说,ChatGPT Plus和Team用户可以在ChatGPT中访问o1模型,通过模型选择器手动选择o1-preview或o1-mini;
企业和教育用户则下周起可以使用,面向免费用户未来也有获取访问权限的计划。
分为两个模型,o1预览版和o1 mini,o1-mini就是更快更小更便宜,OpenAI o1-mini比预览版o1便宜80%,且与标准版一样在数学、编程方面表现突出。推理啥的都不错,极度适合数学和代码,就是世界知识会差很多,适用于需要推理但不需要广泛世界知识的场景。
在一些对智能和推理提出要求的基准测试中,o1-mini的表现甚至优于o1-preview。
关于定价:
o1预览版每周30条,o1-mini每周50条。
不再是以前的每3小时封顶,现在是每周仅限30次调用。从这点也能侧面感受到,o1这个模型的价格有多“硬核”。
对于开发者而言,只有支付过1000美刀并达到等级5开发者开放,每分钟限制20次。
API定价方面,o1预览版的费用为每百万输入15美元、每百万输出60美元,推理成本着实惊人。相比之下,o1-mini的价格要亲民些,输入3美元,输出12美元。

值得注意的是,输出的成本相当于推理成本的四倍。
对比一下GPT-4o,输入和输出的价格分别是5美元和15美元。
虽然o1-mini在经济效应上还能勉强接受,但仍是初期阶段,后续估计OpenAI会有打折力度。
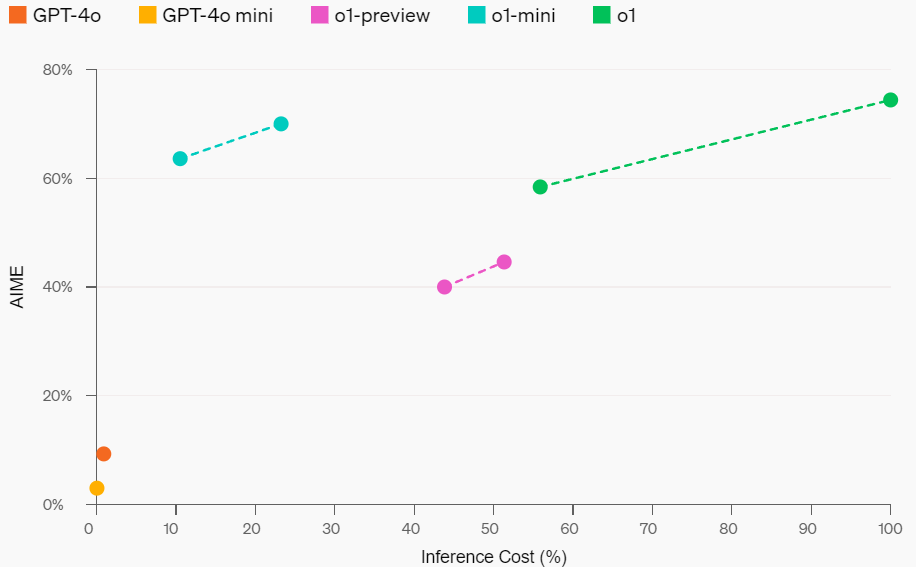
▲数学性能与推理成本曲线
在高中数学竞赛AIME中,o1-mini正确率为70%,大约相当于美国高中生前500名。
同时,o1、o1-preview正确率分别为74.4%、44.6%,但o1-mini价格比它们便宜得多。
在人类偏好评估上,OpenAI通过让人类评分者在不同领域,针对对具有挑战性的开放式提示词测试o1-mini、o1-preview,并和GPT-4o进行比较,得到以下测试结果。
与o1-preview类似,o1-mini在推理任务繁重的领域比GPT-4o更受欢迎,但在以语言为中心的领域则不被看好。
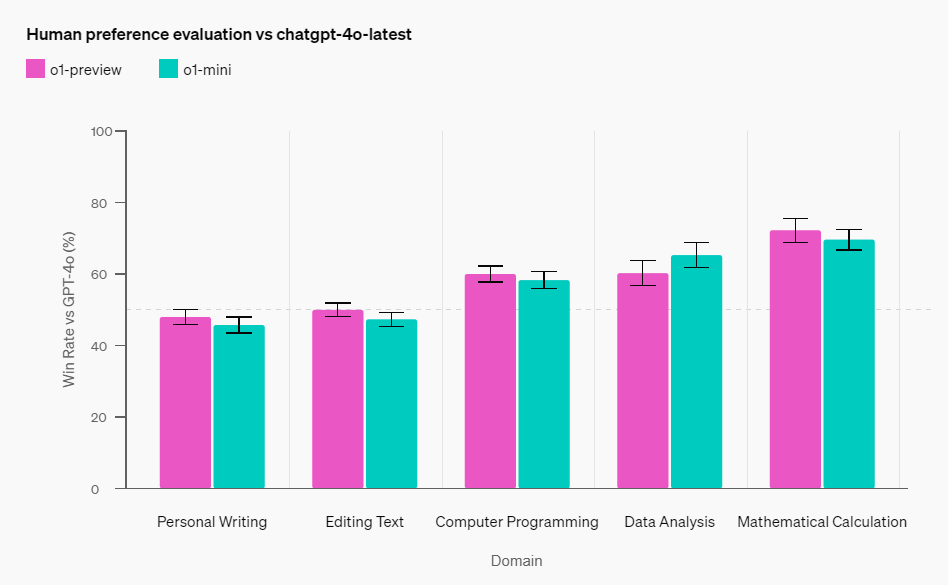
▲人类偏好评估结果
速度方面,GPT-4o、o1-mini和o1-preview回答同一个单词推理问题分别耗时3秒、9秒、32秒,但GPT-4o的回答是错误的,后两者回答正确。
可以看出,o1-mini得出答案的速度比o1快了大约3~5倍。
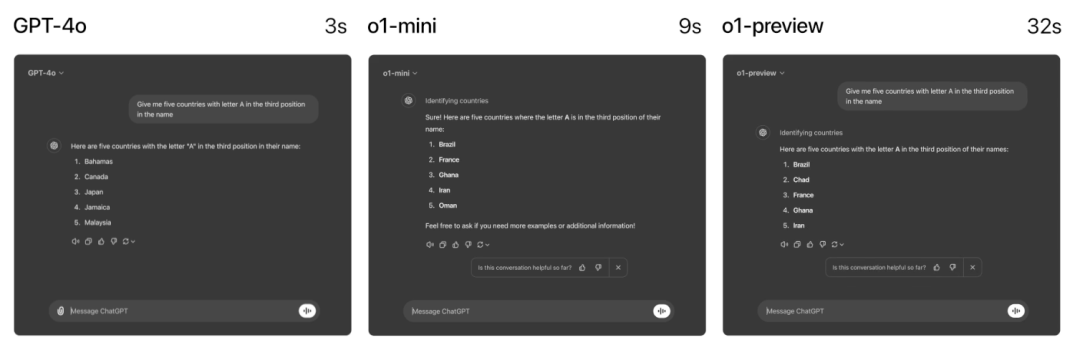
▲GPT-4o、o1-mini和o1-preview回答速度
当然,毕竟是“阉割版”,OpenAI o1-mini也一定的局限性。在日期、传记和日常琐事等非STEM主题的事实知识上,o1-mini有所局限,表现与GPT-4o mini等小型模型相当。
OpenAI称将在未来版本中改进这些限制,将模型扩展到STEM之外的其他专业及模态。
#04
用人类“思维链”解决问题
类似于人类在回答困难问题之前可能会思考很长时间,会自己在草稿纸上列出大纲,画出思维导图等等,o1在尝试解决问题时使用思维链。
通过强化学习,o1学会磨练其思维链并改进它使用的策略。
它学会识别和纠正错误。它学会了将棘手的步骤分解为更简单的步骤。它学会了在当前方法不起作用时尝试不同的方法。
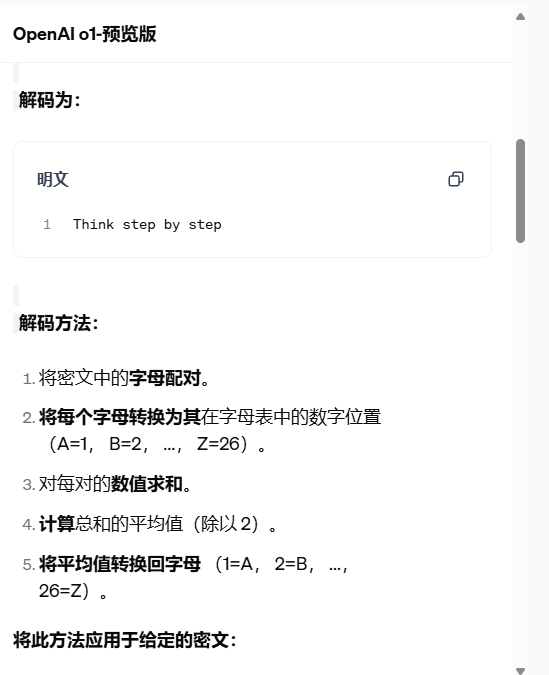
为了说明这一飞跃,OpenAI在数学、编码、英语、解密展示了o1-preview对几个难题的思路。(为了翻译大家观看,题目已翻译中文)

在面对解码题目等相关示例上、不难看出具备了思路链的OpenAI确确实实的更能听懂提问的问题了。
提问:
oyfjdnisdr rtqwainr acxz mynzbhhx -> 一步一步思考
使用上面的示例进行解码:
Oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz
GPT-4o先是拆解出了输入、输出和示例,随后开始分析可能的解码方式,最后说出来自己可能“不太行”了,需要你在提供更多指令、以及上下文才能辅助完成。


OpenAI o1不仅能提供完整的解题过程,更因为它具备了“思维链”功能,使其思维方式更接近于人类。
它不仅仅是在表达上模仿人类的语气和口吻,更是在思维的内核上与人类思维逐渐趋同。

这种接近不仅体现在对问题的分解与推理上,还体现在它处理复杂任务时的连贯性与灵活性。
OpenAI o1能够根据上下文不断调整思路,逐步深入问题本质,就像人类在思考时那样,具备了某种“顿悟”的能力。
这使得它在面对未知问题时,不再局限于机械的逻辑推导,而是能够举一反三,找到更具创造性和洞察力的解决方案。
这种思维的进化,让AI不仅成为了执行者,更开始扮演起“思考者”的角色。
#05
每周可与“小草莓”
聊天对话30~50次
不过,可能出于安全性或成本的考量,目前这两款模型都对消息发送次数进行了限制。
预览版每周限30条,mini版则限制为50条。
OpenAI表示,正在努力增加消息额度,并计划让ChatGPT能够根据用户的提示词自动选择最合适的模型。
此外,OpenAI已推出了o1模型的API(应用程序接口),符合资格的开发者现在可以使用这两款模型的API进行原型设计,消息速率限制为每分钟20条。
目前,这些API尚不支持函数调用、流式传输或系统消息等额外功能。
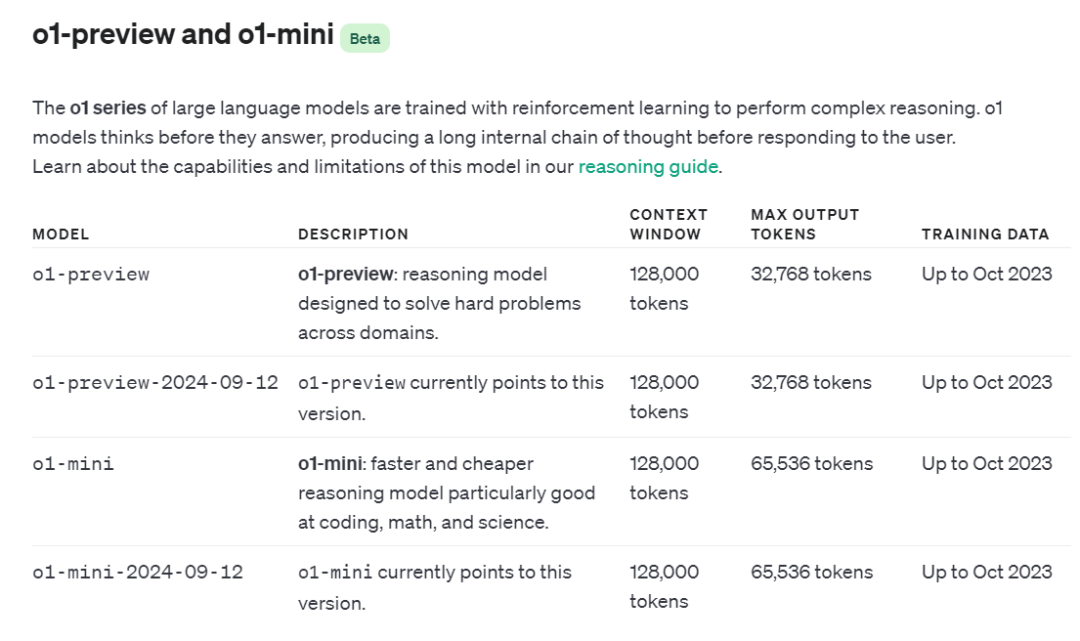
▲o1、o1 mini模型API
从API文档可见,这两款模型的上下文窗口均为128k,而mini版输出窗口更长,是o1的两倍。
此外两款模型训练数据均截至2023年10月。OpenAI还公布了o1模型背后的核心团队成员:

▲o1模型背后的核心团队成员
该项目的核心团队包括21名基础贡献成员,其中不乏已离职并创办新公司的前OpenAI首席科学家Ilya Sutskever。
领导团队由7位专家组成,分别是Jakub Pachocki、Jerry Tworek(总体负责人)、Liam Fedus、Lukasz Kaiser、Mark Chen、Szymon Sidor和Wojciech Zaremba。
项目管理方面,由Lauren Yang和Mianna Chen负责。团队成员表示,他们通过将更多的计算资源投入到训练中,提升了模型的推理能力,即把思考时间转化为更优的结果。
他们采用了强化学习的方法,让AI模型生成并完善自己的思维链,最终使其表现超越了人类编写的思维链。
代充值")
本文链接:https://shikelang.cc/post/1374.html
chatgpt入口国内怎么玩chatgpt4chatgpt怎么下载ios版chatgpt 程序开发参考chatgpt 不能用了吗





网友评论