

先做个广告:如需代注册ChatGPT或充值 GPT5会员(plus),请添加站长微信:gptchongzhi
OpenAI-o1的技术突破
作为一个大模型的初学者,介绍一下OpenAI-o1的技术突破。
推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
新增技术
最近更新的OpenAI-o1增加了以下两点:
more train-time compute to teach "thinking"
即 在训练时,教会模型思考
test-time computer where model spend more inference time of on tokens to exhibit thinking
即 模型 在作答时,思考
Let's Verify Step by Step
去年5月份 openai的论文:Let's Verify Step by Step 中使用outcome supervision或process superviosn 来检测模型幻觉。
outcome supervison:ORM 在最后一步进行supervison,即只关注结果
process supervison :PRM 在过程中supervison,即关注过程
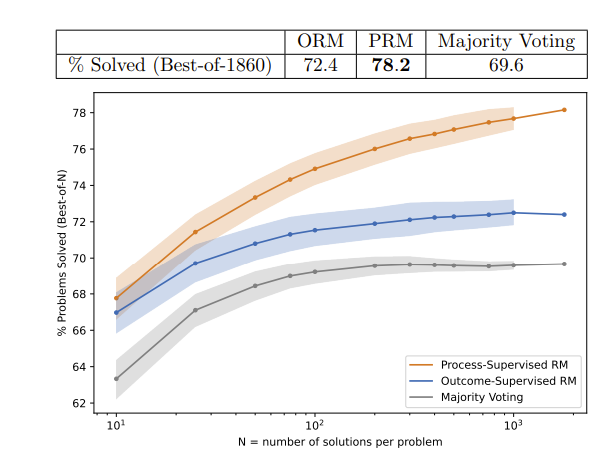
图片出自 Let's Verify Step by Step
Outcome supervison
Outcome supervision中,OpenAI使用数学训练集和程序训练集来训练reward model。
因为数学题和程序的答案确定,因此reward model不需要human-label。
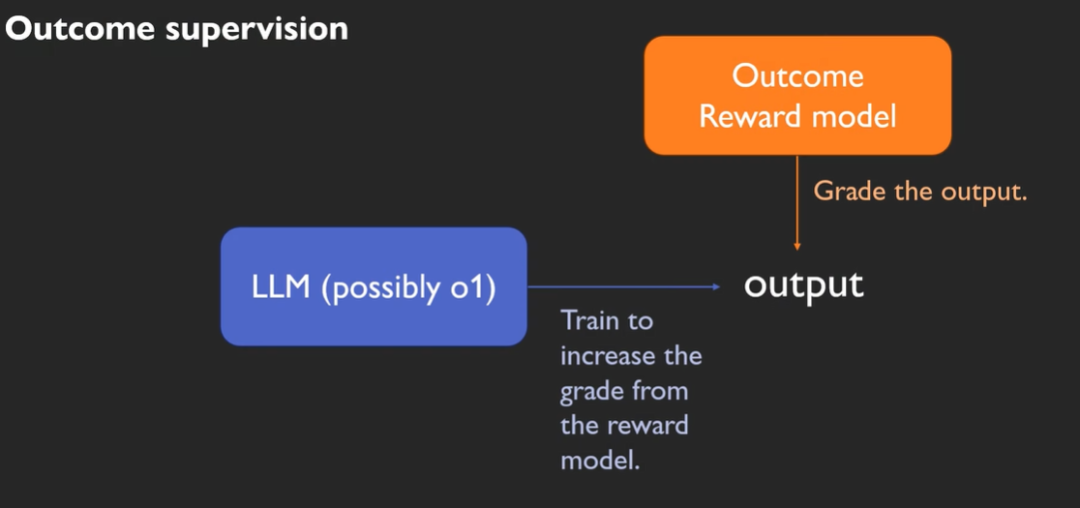
背景知识 chain_of_thoughts
如果我们将大模型肤浅的理解成,预测下一个单词的概率,那么降低大模型幻觉的一种方式就是chain of thoughts,更简单的一个例子就是lets think step by step。
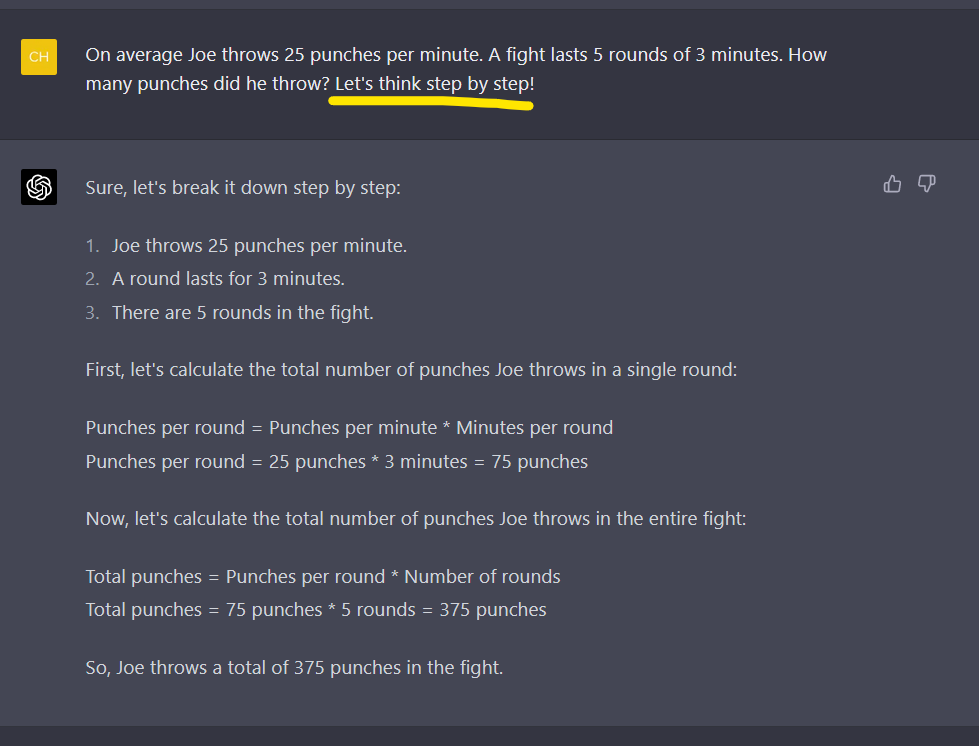
可以理解成是在模型已经成型之后,在我们使用模型时,在我们输入的问题prompt中,手动添加lets think step by step。
这样暗示大模型将复杂问题可以一步一步分解,一步一步预测下一个token的概率。
Process supervison
chain of thoughts是在大模型已经定型时,才lets think step by step。
Process supervision则是在大模型的训练过程中,就将chain of thoughts引入。
同样是在 Let's Verify Step by Step的论文中,他们依赖human data-lablers 大模型数据标注师来处理process supervison。


如上图所示,可以在每一步都进行反馈。
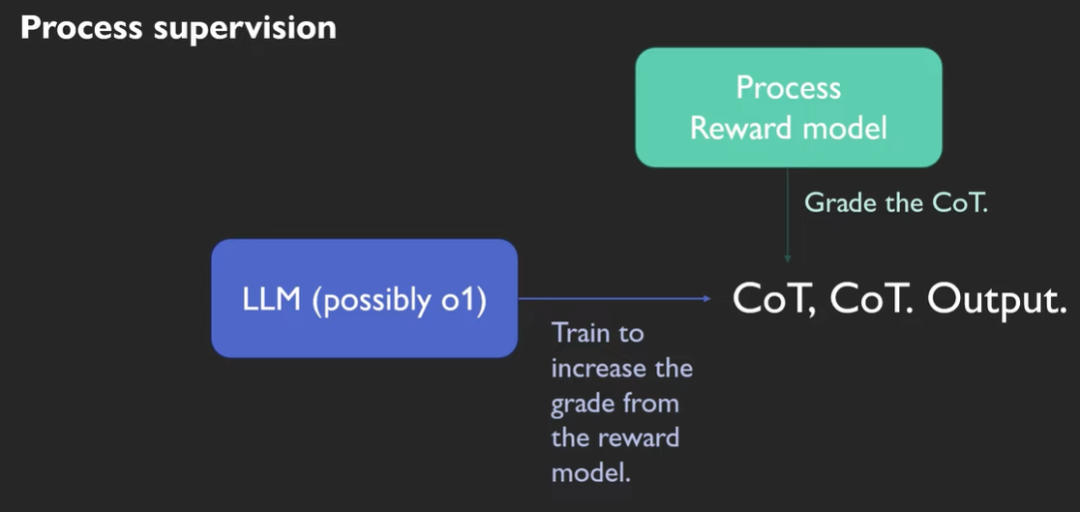
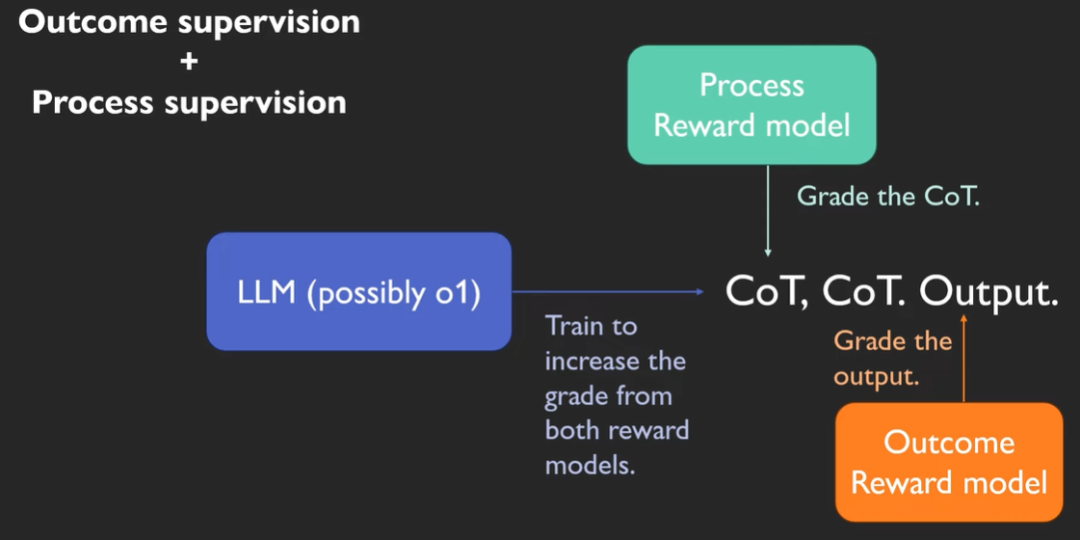
Outcome & Process supervison
Outcome/Process supervison各自训练对应的奖励模型reward model。
Process Reward Model负责改善chain of thoughts。
Outcome Reward Model负责改善最终结果。
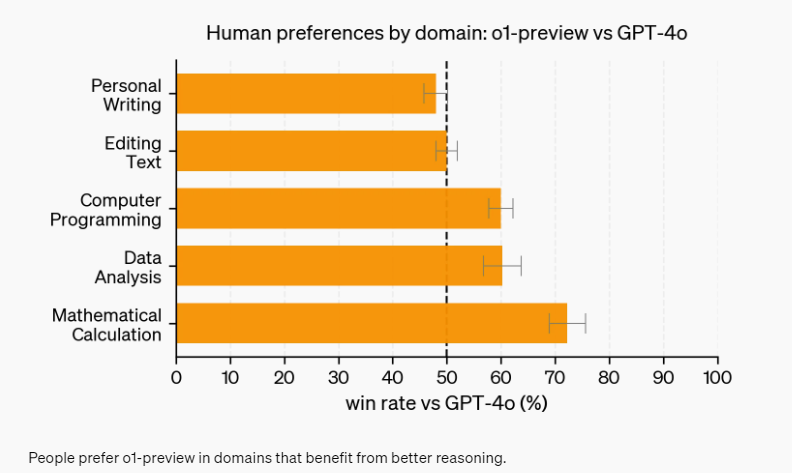
GPT-o1相对于GPT-4o的效果
正如上文所说,对于复杂且答案唯一的问题,比如数学和编程问题,这个方法非常有效。
因为答案唯一。
下图为OpenAI官网截图,如图所示,在上面两行的writing和text中,OpenAI-o1的模型效果并没有增强。
但是对于编程,数学分析,数学计算,模型效果相对于GPT-4o明显增强。
More Complex & More Time
因为chain-of-thoughts的引入,gpt-o1在使用时,也会使用chain of thoughts,他们称之为reasoning token。
以下是官网介绍的:
How reasoning works 推理如何运作
The o1 models introduce reasoning tokens. The models use these reasoning tokens to "think", breaking down their understanding of the prompt and considering multiple approaches to generating a response. After generating reasoning tokens, the model produces an answer as visible completion tokens, and discards the reasoning tokens from its context.
o1 模型引入了推理token。这些模型使用这些推理token来“思考”,分解他们对提示的理解,并考虑多种方法来生成响应。生成推理token后,模型会生成一个答案作为可见的完成token,并从其上下文中丢弃推理token。
Here is an example of a multi-step conversation between a user and an assistant. Input and output tokens from each step are carried over, while reasoning tokens are discarded.
以下是用户和助理之间的多步骤对话的示例。每个步骤的输入和输出token都会被保留,而推理token将被丢弃。
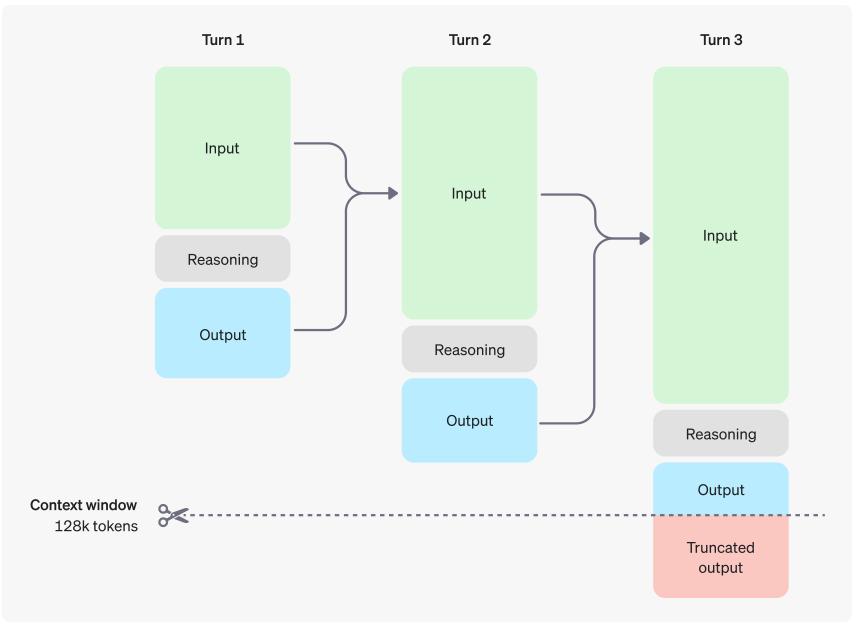
这样的处理方式可以解决复杂问题,但是相应的也导致处理问题的时间更长。
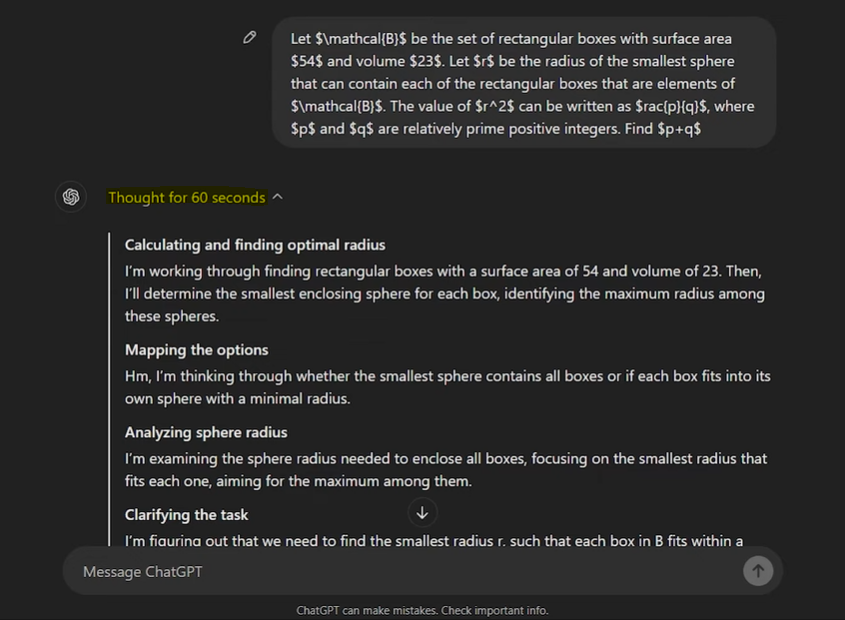
strawberry里面有几个r
这次OpenAI-o1展示自己的思考能力的一个例子就是这个模型可以正确回答:
strawberry里面有几个r。
这个问题复杂在哪里呢?
这是因为在训练大模型时,会先将单词word映射成向量,即tokenization。
一种常见的做法是先将word切分成subword,再把subword映射到向量。
该方法在bert和GPT中也有使用。

来自reddit帖子中的一个回答,
如果问school中有几个o,subword tokenization把school切成了scho和ol,并且将两个subword:scho和ol都映射到了向量数字,那么如果我们直接问大模型school中有几个o,大模型只能看到scho和ol对应的向量,是无法推理出有几个o的。
具有“思考能力”的OpenAI-o1模型,终于可以正确的回答这个问题了。
本文参考以下内容
https://www.reddit.com/r/OpenAI/comments/1e6dl54/why_the_strawberry_problem_is_hard_for_llms/
https://people.cs.umass.edu/~miyyer/cs685/slides/tokenization.pdf
https://platform.openai.com/docs/guides/reasoning
https://cdn.openai.com/improving-mathematical-reasoning-with-process-supervision/Lets_Verify_Step_by_Step.pdf
代充值")
本文链接:https://shikelang.cc/post/1383.html
OpenAI-o1OpenAI o1OpenAI01chatgpt o1o1-minio1-previewOpenAI o1 miniOpenAI o1 previewOpenAI o1官网OpenAI o1官网入口OpenAI o1地址OpenAI o1中文版openai o1模型简介





网友评论