

先做个广告:如需代注册ChatGPT或充值 GPT5会员(plus),请添加站长微信:gptchongzhi

 推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
美西时间9月12日,OpenAI发布了新推理系统o1,这是人工智能领域的一次重要进展。o1系统基于早期的Q*项目以及最近传闻中的“Strawberry”项目,采用了一种全新的方式来处理复杂任务。与传统的自回归模型(autoregressive language models)不同,o1为用户进行实时在线搜索,并大量使用强化学习,推动了AI能力的进一步扩展。这一系统还揭示了新的“推理扩展定律”(inference scaling laws),表明增加推理计算的投入可以提高输出的准确性。
一、从 Q* 到草莓(Strawberry)再到 o1
OpenAI最新的o1模型发布已经酝酿了一段时间,特别是去年11月领导层动荡时的泄密事件引发了广泛关注。当时的消息透露,这个新模型具备强大的计算资源,能够解决某些数学问题,令研究人员非常兴奋。这个早期成果展示了训练过程中巨大的潜力,尤其是基于Q*方法的模型——内部代号为“Strawberry”(草莓)——在生成文本时能够进行推理,采用某种树状推理搜索的方式。
o1并非仅仅是一个语言模型,而是一个复杂的系统。它通过将高级计算过程转化为连贯的输出,接近一种闭环控制系统的形式,这在语言建模领域是前所未有的。扩展这个系统必然是一项巨大的挑战,尽管目前o1仍处于预览阶段,但它的发展路线与过去的强化学习(RL)突破,如AlphaGo,具有相似性。o1将成为未来众多产品的核心推理引擎,具有广阔的应用前景。
o1系统通过强化学习,以非常高效的数据方式训练模型,极大提升了模型的性能——无论是在训练时通过更多计算资源,还是在测试时通过增加推理时间。这个方法与通常的LLM预训练扩展策略有很大不同,更加注重高效推理。
尽管取得了这些突破,当前发布的o1预览版并不是OpenAI的最顶尖模型。根据测试结果,它的性能位于GPT-4和完整的o1模型之间。
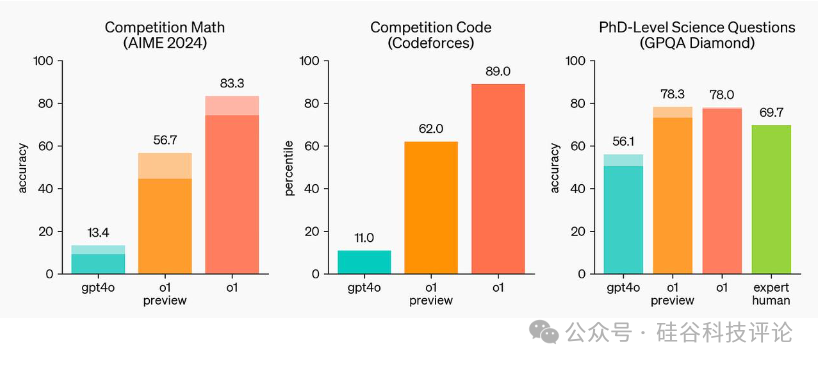
o1在其他基准测试中的得分不一,例如在ARC-AGI和aider编程挑战中与Claude 3.5的结果相似。在数学、物理等科学问题面前,表现很出色。此外,OpenAI提供了更多关于完整o1系统(注意,不是预览版)的评估。
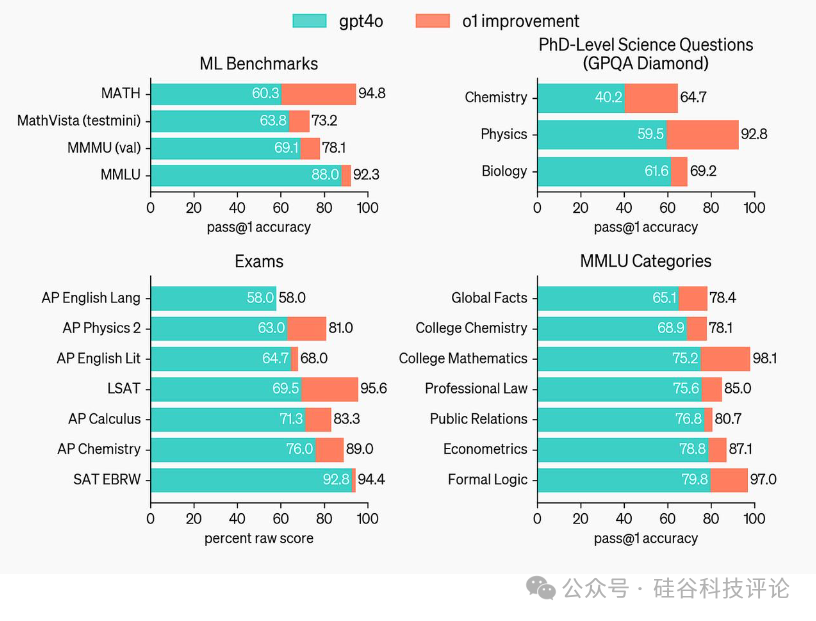
OpenAI本次只发布预览版,而非最终版,可能是因为:
无法向用户提供最强配置,因为成本太高。
没有足够的基础设施来部署最终版本。
最终版本可能还没有达到他们的安全标准。
无论如何,o1仍然是一个颠覆性的新AI模型。英伟达的高级研究人员Jim Fan总结了下一代AI系统在计算资源消耗方面的变化,认为o1是向真正的语言模型代理过渡的开始。

o1这种方法并非对每个查询都经济有效。像下面这种简单的查询在这个系统中会消耗高达225个Token。而正常的模型应该只需要10到12个Token。我们认为,ChatGPT最终会通过路由的方式,将你的查询引导到正确的模型。
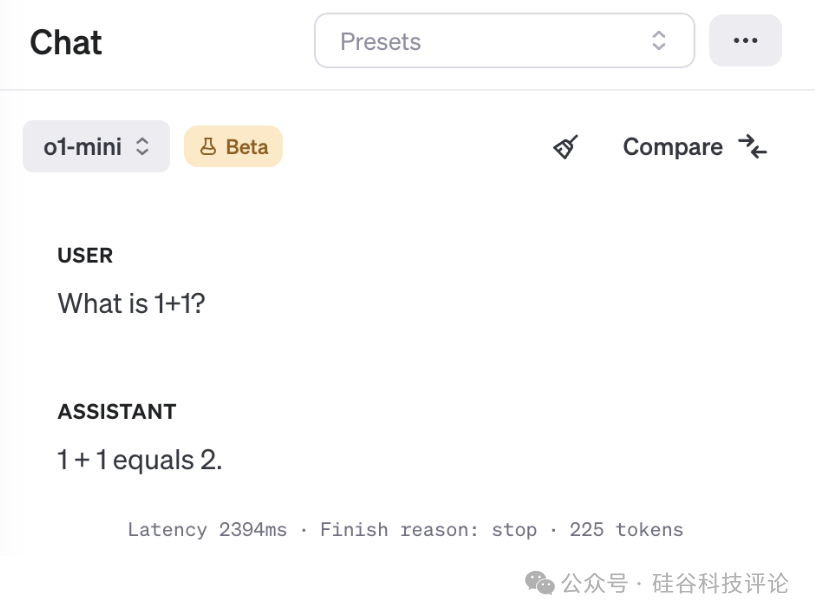
二、使用强化学习训练 o1模型
OpenAI 最近发布的 "o1" 是人工智能领域的一个重大突破,尤其是在大规模部署方面。o1 能够进行大规模文本搜索,这标志着从传统语言模型向更加具备自主性的 AI 系统的转变。虽然 o1 的具体工作机制仍然不完全清楚,但可以确定的是,它采用了基于强化学习(RL)的算法。
与一些可以回溯推理的旧系统不同,o1 的强项在于一步接一步地构建推理过程,符合强化学习中“前向生成”的概念。这种方式与传统强化学习领域(如游戏)中的规则一致,在这些领域中,动作一旦执行便无法撤销。对于 o1 来说,每生成一个词就相当于采取一个动作,而这些动作会不断扩展上下文(即“状态”),这种复杂且不断增长的轨迹管理正是 o1 的关键创新点之一。
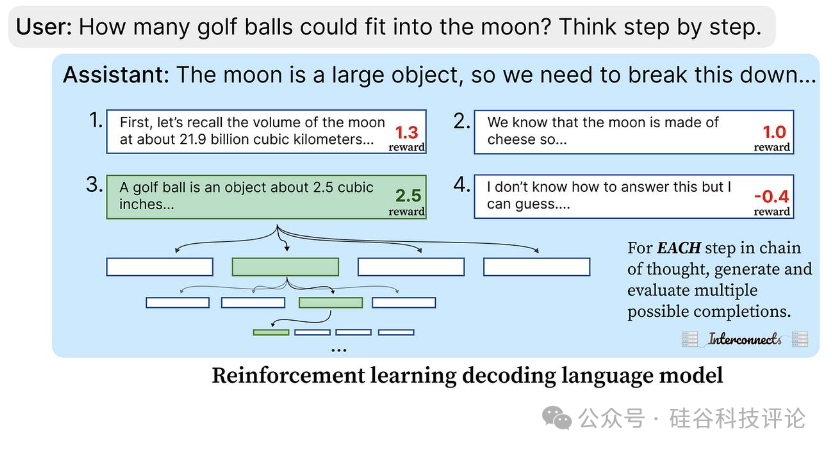
在强化学习应用于语言模型时,一个主要挑战是奖励的分配。在传统的 RL 中,奖励往往是二元的,并且通常在整个序列结束时分配,这使得很难识别模型在哪一步犯了错误。最新的研究则通过“过程奖励模型”解决了这个问题,该模型会为推理过程中的每一步进行评分。OpenAI 的 "Let’s Verify Step By Step" 论文展示了如何通过逐步评价来提高模型的准确性。在这个系统中,错误的步骤可以及早被纠正,从而允许 RL 代理根据不同的奖励路径探索和区分正确与错误的推理过程。
探索(exploration)在 o1 的强化学习训练中发挥了至关重要的作用。早期版本的模型行为可能与现有系统(如 GPT-4)相似,但随着奖励机制的引导,模型逐渐发现了新的推理步骤。这种探索对于模型性能的持续改进至关重要;如果没有广泛的状态探索,模型的表现可能会趋于停滞,甚至出现过拟合或性能下降的情况。
三、o1 的成本为什么那么高?
OpenAI 的 o1 模型之所以推理成本高,主要原因在于其独特的解码过程,结合了生成模型和强化学习(RL),与之前的模型如 GPT-4 有很大的不同。o1 每个输入和输出 token 的高昂价格,反映了这种新方法的复杂性,而不是因为模型本身更大。实际上,o1 可能并不比 GPT-4 大,但每个 token 执行的计算量要多得多,因为它在生成多个候选答案后会对其进行评估和打分。
与传统的自回归模型只预测下一个 token 不同,o1 似乎采用了并行解码的策略。对于每个推理步骤,模型会生成多个候选输出,并在完成这个步骤后对它们进行打分。这种生成、打分和选择的过程可能是推理过程中计算成本高的主要原因,因为它需要分支生成多个潜在的继续路径,然后从中选择最优解。
这种方法与传统的自回归模型相比,有着本质的不同,因为它在生成每一步时必须考虑多个候选方案并进行并行评估,而不是按顺序一步步生成 token。这种并行解码方式也解释了为什么 o1 的推理比一般的聊天模型贵得多。目前o1-preview 每百万个输入token收费 15 美元,每百万个输出token收费 60 美元。这个价格是GPT 4o mini的10倍。
四、o1模型的壁垒和未来
在o1模型推出之际,海内外又在讨论OpenAI的技术先进性和国内的差距。目前看来,复制这种先进AI系统还面临诸多挑战,包括:
模块化和保密性:创建类似于o1的系统比复制ChatGPT这样的模型要复杂得多,因为模块化AI系统中的各部分之间有着紧密的相互作用。这些系统对其模块如何连接非常敏感。OpenAI很谨慎,没有公开其模型的工作原理,这使得复制更加困难。
种子数据与初始训练:OpenAI很可能聘请了高技能的标注员来生成复杂的推理路径,使用多种方法来解决问题,从而创建有价值的训练数据。仅仅复制推理轨迹是不够的,因为这些模型可能还使用了对比学习(contrastive learning)来进一步优化决策能力。
成本与计算资源:生成和过滤模型输出的成本可能是现有语言模型的10倍、100倍甚至1000倍。尤其是在涉及RL(强化学习)的情况下,需要数十万的样本数据来进行训练。目前只有少数几家大公司能够承担。
展望未来,o1模型可能不仅限于数学领域,还会扩展到工具使用等其他领域。ChatGPT未来或许会自动调用o1进行某些任务,提升其整体能力。此外,保持o1模型的独立性可能并不现实,它很可能会与其他系统进行整合。
最终,随着AI技术的快速发展,这些系统将表现出越来越独立的行为模式,人类监督会逐渐减少。类似AlphaGo的“第37步”(人类看来的臭棋,却是取得关键致胜的一招)的语言领域革命性时刻,也许很快就会出现。
代充值")
本文链接:https://shikelang.cc/post/1386.html
股票量化策略chatgpt每次都需要登录吗chatgpt4.0是哪个国家发布的chatgpt4能通过图灵测试吗用chatgpt写论文知网查重





网友评论