

先做个广告:如需代注册ChatGPT或充值 GPT5会员(plus),请添加站长微信:gptchongzhi
OpenAI推出全新功能,让ChatGPT输出速度大幅提升!
 推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
这个新功能名为“预测输出”(Predicted Outputs),在其加持下,GPT-4o的响应速度可以提高最多5倍。
让我们通过编程示例来亲身体验这一变化的速度感受:

为什么会这么快?简单来说,就是:
跳过已知内容,避免从头开始重新生成。
因此,“预测输出”非常适合以下任务:
在文档中更新博客文章
迭代先前的响应
重写现有文件中的代码
而且,与OpenAI合作开发这一功能的FactoryAI,也展示了他们在编程任务中的数据成果:
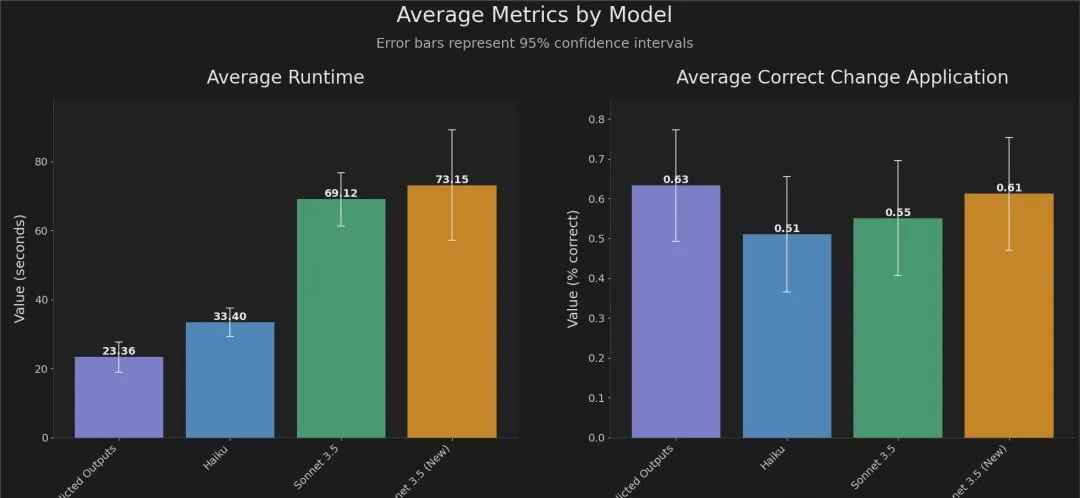
从实验结果来看,借助“预测输出”功能,GPT-4o的响应时间比之前提高了2到4倍,同时保持了高精度。
官方还表示:
原本需要70秒完成的编程任务,现在只需要20秒。
值得注意的是,目前“预测输出”功能仅支持GPT-4o和GPT-4o mini两个模型,并且是通过API形式提供。
对于开发者而言,这无疑是一个重大的利好消息。
网友在线实测
消息一出,许多网友迫不及待地进行实测。
例如,Firecrawl创始人Eric Ciarla就使用“预测输出”功能,体验了将博客文章转化为SEO(搜索引擎优化)内容的过程。他表示:
速度真是快得令人惊讶。
就像在API调用中轻松添加一个预测参数一样简单。
另一位网友则是在现有代码的基础上,输入了一个简单的Prompt:
"change the details to be random pieces of text."
他表示,这样的操作体验让他切实感受到了速度的提升:

还有网友分享了自己实测的数据显示:
总的来说,速度,真的是飞快。
这是怎么做到的?
关于“预测输出”的技术细节,OpenAI在官方文档中也进行了详细介绍。

OpenAI认为,在某些情况下,LLM的大部分输出实际上是可以预见的。
如果你要求模型仅对某些文本或代码进行细微修改,借助“预测输出”功能,就能将现有内容作为预测输入,从而显著降低延迟。
举个例子,假设你想重构一段C#代码,将 Username 属性改为 Email:
////// Represents a user with a first name, last name, and username.///public class User{////// Gets or sets the user's first name.///public string FirstName { get; set; }////// Gets or sets the user's last name.///public string LastName { get; set; }////// Gets or sets the user's username.///public string Username { get; set; }}
你可以合理假设,文件的大部分内容是不会被修改的(比如类的文档字符串、一些现有的属性等)。
通过将现有的类文件作为预测输入,你可以更快地重新生成整个文件。
import OpenAI from "openai";const code = `////// Represents a user with a first name, last name, and username.///public class User{////// Gets or sets the user's first name.///public string FirstName { get; set; }////// Gets or sets the user's last name.///public string LastName { get; set; }////// Gets or sets the user's username.///public string Username { get; set; }}`;const openai = new OpenAI();const completion = await openai.chat.completions.create({model: "gpt-4o",messages: [{role: "user",content: "Replace the Username property with an Email property. Respond only with code, and with no markdown formatting."},{role: "user",content: code}],prediction: {type: "content",content: code}});// Inspect returned dataconsole.log(completion);
使用“预测输出”生成tokens会大幅降低这类请求的延迟。
不过,OpenAI官方也给出了几点注意事项,特别是在使用“预测输出”时需要留意的细节。
首先,正如我们刚才提到的,当前此功能仅支持GPT-4o和GPT-4o-mini系列模型。
其次,以下API参数在使用“预测输出”时是不被支持的:
n values greater than 1
logprobs
presence_penalty greater than 0
frequency_penalty greater than 0
audio options
modalities other than text
max_completion_tokens
tools - function calling is not supported
除此之外,在这份文档中,OpenAI还总结了几个除了“预测输出”之外的延迟优化方法。
这些方法包括:“加速处理token”、“生成更少的token”、“使用更少的输入token”、“减少请求”以及“并行化”等等。
文档链接已放在文末~
One More Thing
尽管输出速度变快了,但OpenAI还有一个注意事项引发了网友们的讨论:
"When providing a prediction, any tokens provided that are not part of the final completion are charged at completion token rates."
翻译过来就是:在提供预测时,所提供的任何非最终完成部分的tokens都将按完成tokens的费率收费。
一些网友也分享了他们的测试结果:
未采用“预测输出”:5.2秒,0.1555美分
采用了“预测输出”:3.3秒,0.2675美分

嗯,速度变快了,但也更贵了。
OpenAI官方文档:
https://platform.openai.com/docs/guides/latency-optimization#use-predicted-outputs
参考链接:
[1]https://x.com/OpenAIDevs/status/1853564730872607229
[2]https://x.com/romainhuet/status/1853586848641433834
[3]https://x.com/GregKamradt/status/1853620167655481411
代充值")





网友评论