

先做个广告:如需代注册ChatGPT或充值 GPT5会员(plus),请添加站长微信:gptchongzhi
“ 2024年12月5日太平洋时间上午十点(北京时间6号凌晨2点),OpenAI准时开启了十二天连续直播之Day 1。”
 推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
在今天的直播中,OpenAI核心发布了2个产品:
第一,一个超级贵的订阅服务,200美元/月的ChatGPT Pro
第二,更快、更智能和对多模态能力支持有点“瘸腿”的正式版o1模型
01
—
So,200美元/月的ChatGPT Pro贵在哪里?
ChatGPT Pro涵盖的功能包括无限制使用o1模型、o1-mini模型、GPT-4o模型、Advanced Voice(高级声音)模型、和号称高度智能的o1 Pro模式(o1模型的高级版本)。ChatGPT Pro的目标用户是科学家/研究者、工程师和需要日常运用科研级别人工智能能力的个人。
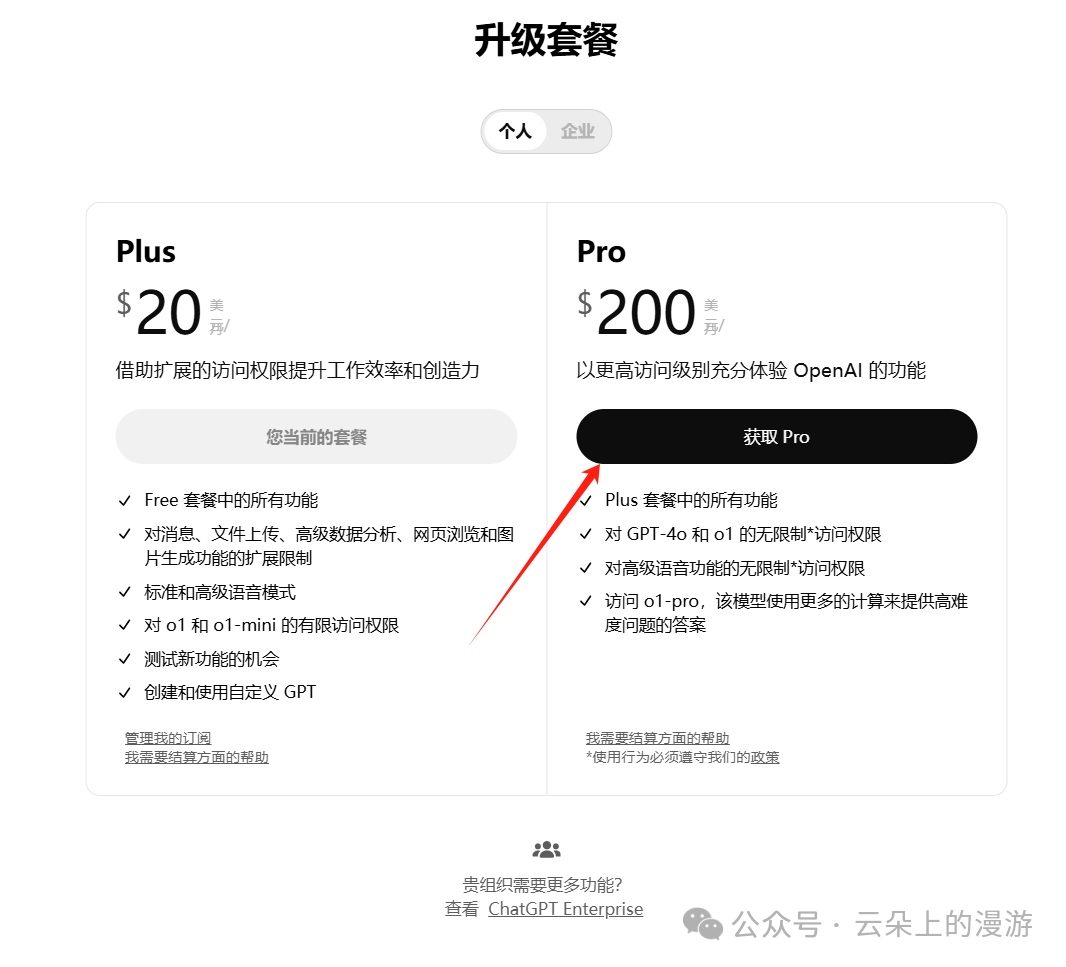
本文发布后,笔者会立刻下单
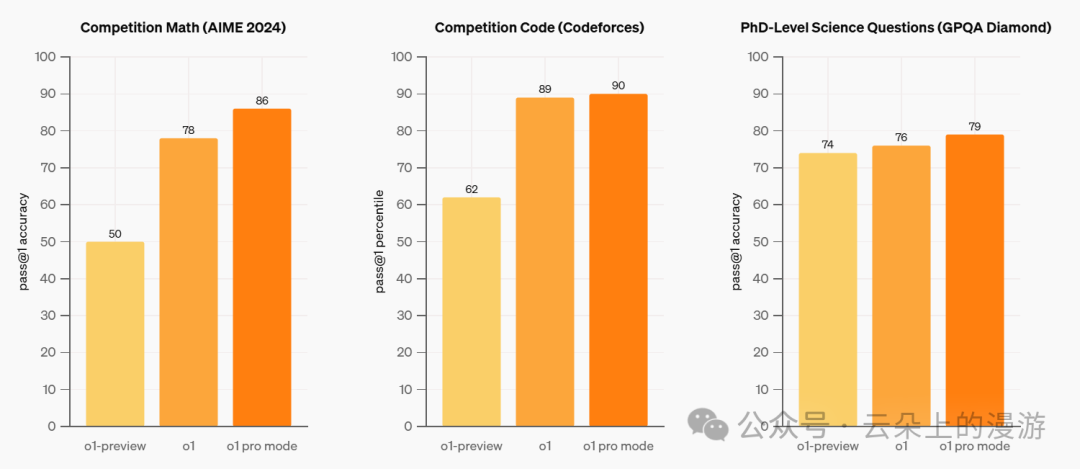
此外,OpenAI强调o1 Pro的可靠性比其他模型更强,只有当模型在四次回答问题都正确的时才算回答正确,以这种更严格的标准测试,o1 Pro回答复杂数学问题的正确率为80%、竞赛级复杂代码问题为75%、博士级科学问题为74%。
第三,解决复杂问题能力更强、体验更好
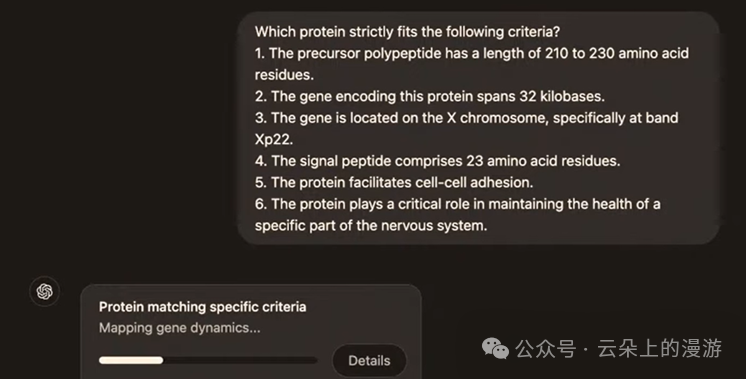
如果用户问了一个复杂的问题,比如“什么样的蛋白质结构严格符合以下六种标准?”,o1 Pro模型不但可以通过思维链交叉验证自己的思考过程,还会提供一个进度条给用户,舒缓等待的焦虑。。
02
—
更快、更智能的o1模型
从o1-preview升级到正式的o1模型后,重大错误的错误率降低了34%,“思考(反应)”速度提高了50%。
OpenAI的研究员举了一个例子,要求模型“列出罗马帝国第二世纪的皇帝,并包括他们的在位日期和主要成就。”
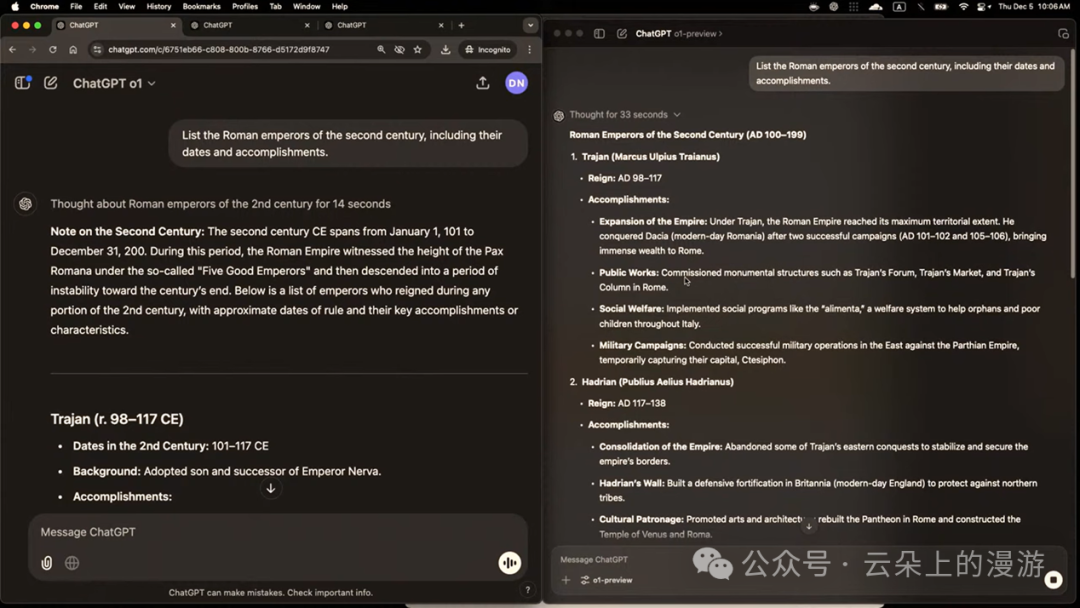 |
03
—
“瘸腿”但重要的多模态特性支持
升级后的o1模型可以支持上传和分析图片了——但是文件上传和互联网检索还需要等一段时间。OpenAI的研究员画了一个“太空数据中心“草图让o1模型完成三个任务:
- 数据中心如何应对太阳辐射和深空环境? - 热力学第一定律在其中如何发挥作用? | 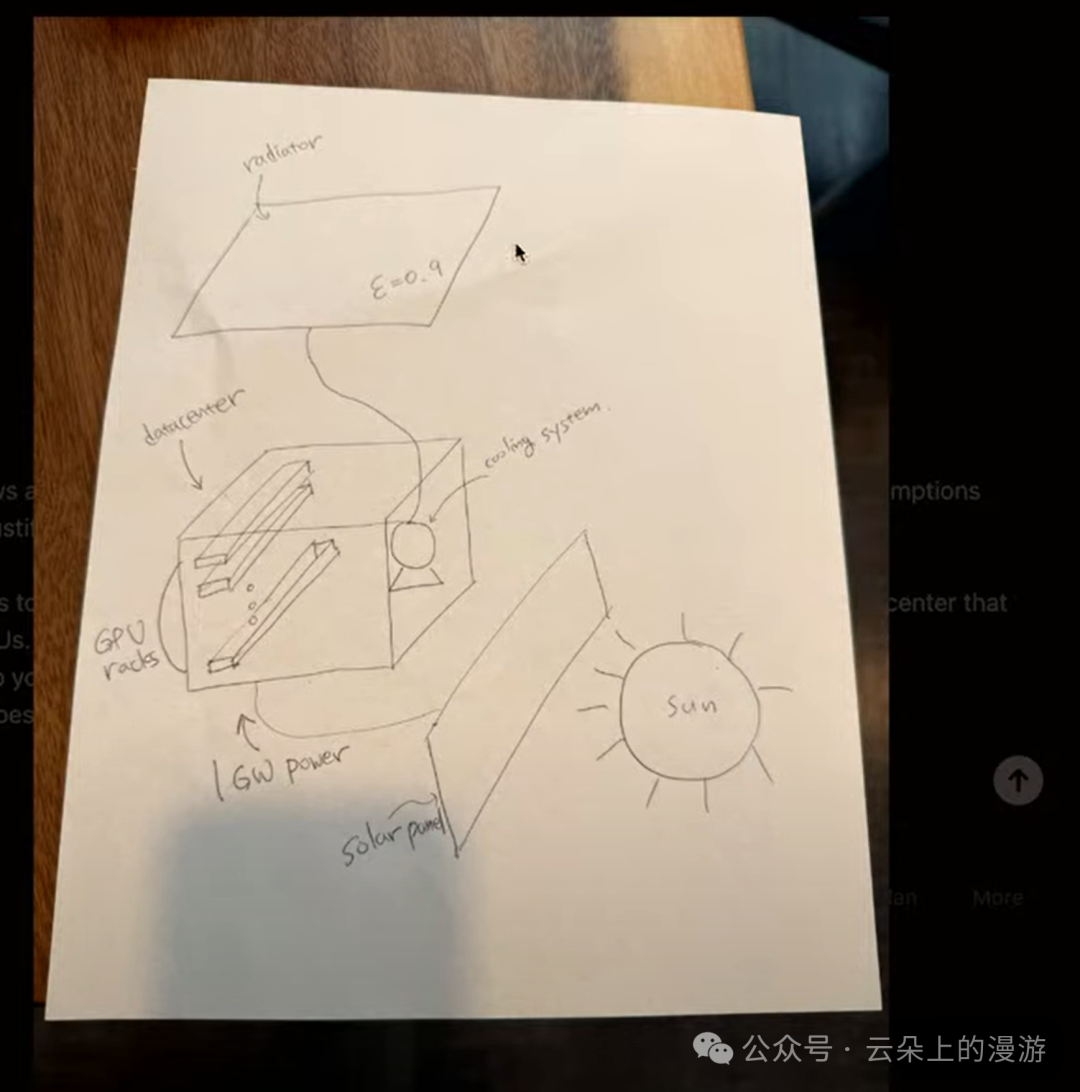 |
OpenAI的研究员标识o1模型回答的还不错,首先模型捕捉到了草图中的一个细节但重要的参数(1 GW的输入功率),并且也领会了研究员故意遗漏的前提条件。
对教育行业的影响:
更好的多模态支持尤其对低龄段教学尤为有益,比如绘本阅读,其实有时候老师打开绘本也不知道该怎么教。我用OpenAI最新的o1正式版模型模拟老师/家长与孩子基于绘本材料的对话,效果令人诧异,对话的流畅性和前后连贯性非常好。
 |   |
放松一下
OpenAI的研究员最后讲了一个冷笑话作为结尾,临近美国圣诞节,圣诞老人尝试用大语言模型解决数学题,他非常努力的使用提示词让大语言模型回答问题但是搞不定,圣诞老人最终解决问题的方式是通过使用“reindeer enforcement learning(麋鹿强化训练学习,强化学习的谐音梗,reinforcement learning)"
代充值")





网友评论