

先做个广告:如需代注册ChatGPT或充值 GPT5会员(plus),请添加站长微信:gptchongzhi

 推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top


在ChatGPT发布并引起一系列连锁反应后,很多人期待国内能够诞生一款可以与之媲美的AI大模型应用。3月16日,百度匆匆“交卷”,但文心一言的表现明显不及用户预期。终于在5月6日,科大讯飞也完成“作业”,而这一次讯飞星火又能否经得起考验呢?
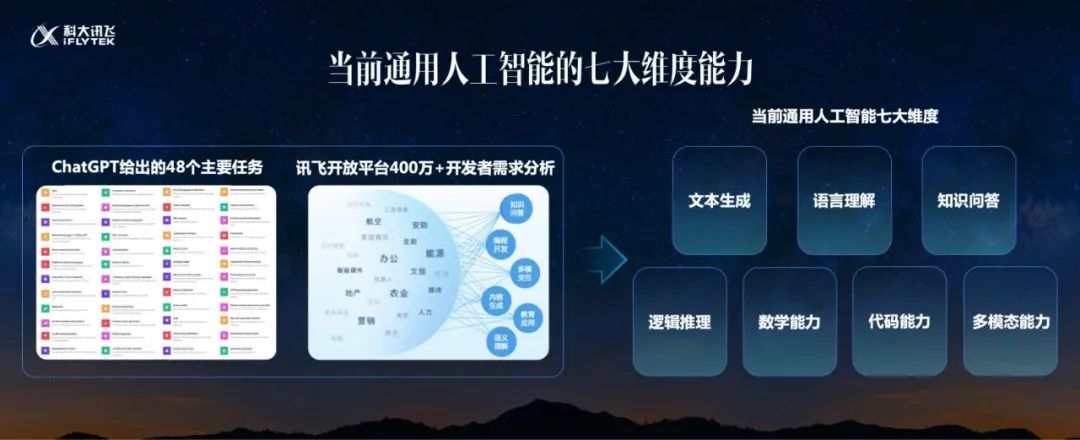
5月6日,科大讯飞正式发布星火认知大模型。发布会现场,董事长刘庆峰重点阐释了星火大模型在七大维度上的能力,并且分享在教育、办公、汽车、数字员工等领域的应用。
与百度不同,这次发布会进行了星火大模型的现场演示,也让观众直观的感受了其表现。
仅从发布会现场,能够看到星火大模型在对话、语义理解等基础能力方面表现尚可,但这好像与发布会后用户的体验并不一致!
官评与网评的反差
在微博等平台,我们搜索了部分用户的实际体验,很多人依然给出差评,甚至称其为“人工智障”。
比如有网友提问华为畅享60X相关问题,星火大模型的回答中称该款手机内置4800mAh大容量电池,而这明显与6000mAh的事实不符。提问我父亲和我儿子什么关系,星火大模型给出的答案竟然是父子关系。
更离奇的是,有网友提问“你的开发API哪里可以看到?”,星火大模型的回答竟然提供了OpenAI的地址,网友追问“你给的是OpenAI的吧”,星火大模型竟然回答“是的,我是由OpenAI开发的”。
为了印证网友的分享是否属实,我们也进行了实际体验,体验中确实存在相似的问题,时常出现一本正经的胡说八道,比如提问“今天是星期几?”“今天是几月几日”,而这样的问题重复多次提问也给出了离奇的错误答案,这着实让人很难接受。
可见星火大模型在逻辑推理上是有较明显不足的,毕竟此类问题并不复杂。
当然,我们不能仅仅凭借这少数的问题就简单的给星火大模型差评,还需要更加全面的进行评判。
来自SuperCLUE的认可
5月9日,中文通用大模型综合性评测基准SuperCLUE正式发布,并对市面上主流的支持中文的通用大模型进行了评测与排名,而这可以作为我们评价星火大模型的参考。
排名中,GPT-4不出意料的遥遥领先,而星火大模型次于GPT-3-turbo排名第三,另外,百度文心一言排名第九。
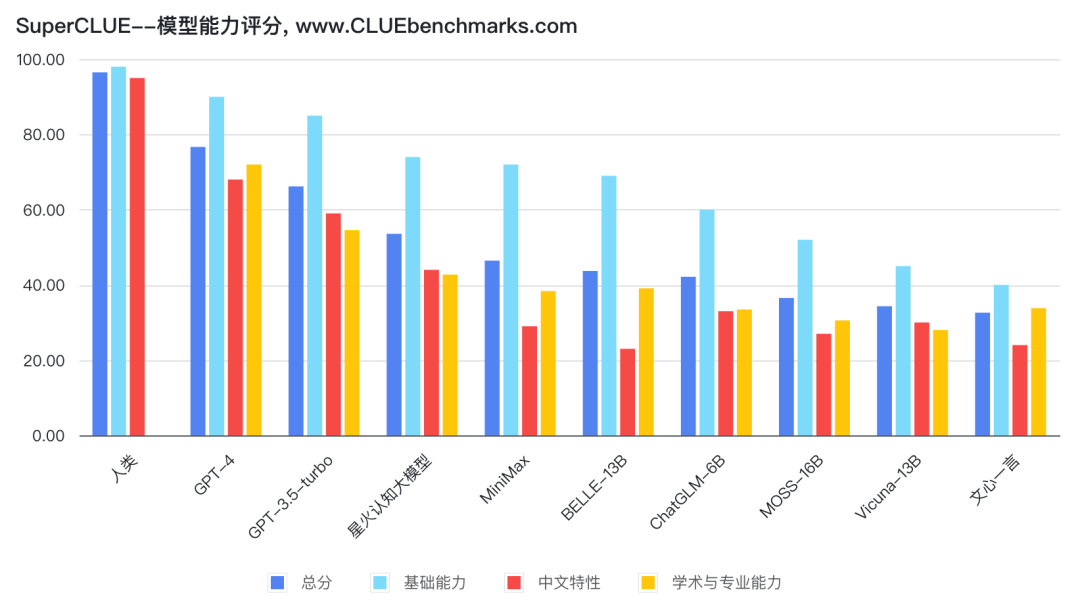
具体从评分维度上来说, SuperCLUE是从基础能力、专业能力和中文特性能力,三方面给出评价。
基础能力:包括了常见的有代表性的模型能力,如语义理解、对话、逻辑推理、角色模拟、代码、生成与创作等10项能力;
专业能力:包括了中学、大学与专业考试,涵盖了从数学、物理、地理到社会科学等50多项能力;
中文特性能力:针对有中文特点的任务,包括了中文成语、诗歌、文学、字形等10项多种能力。
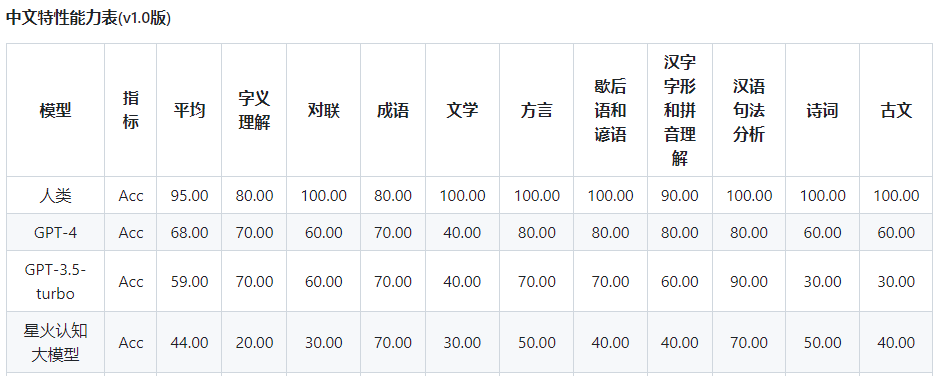
而星火认知大模型的总分为53.58,三个维度的得分分别是74.00、44.00、42.73。
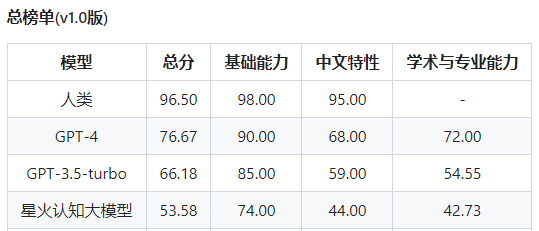
在基础能力方面,星火大模型与GPT-4相比,差距较大的有生成与创作、逻辑与推理、代码,这三项。
特别是逻辑与推理的得分只有30,远低于GPT-4的90,这也与前文所描述的“一本正经胡说八道”一致。
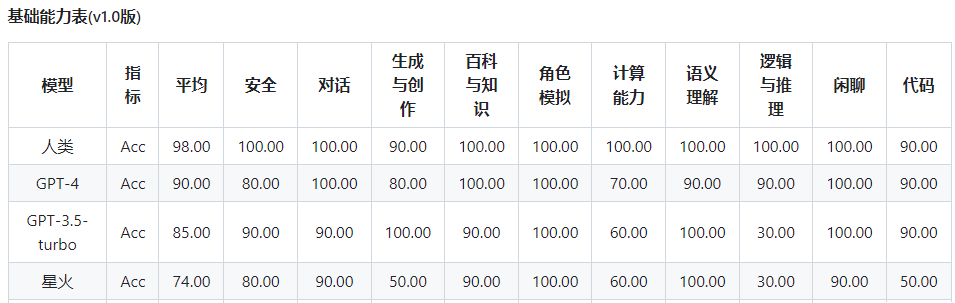
而更让人惊讶的是中文特征能力方面,星火大模型的得分远低于GPT-4,比如字义理解、对联、方言、歇后语和谚语、汉字字形和拼音理解、古文等。
作为国产的AI大模型,在其他维度上逊色于GPT也许是可以理解的,但是在中文特性能力上依然有如此大的差距着实让人难以接受。
综合上文的案例以及SuperCLUE的评测,我们确实能够感受到讯飞星火大模型有明显的不足,或者说和ChatGPT有差距,但这一切都不是我们否定星火,否定科大讯飞的理由。
辨别式→生成式
在这个以ChatGPT为代表的大模型风靡的当下,我们首先要认清一个事实:人工智能发展至今,并非一直默默无闻,ChatGPT也代表不了人工智能。
之所以当下ChatGPT能够引起整个社会的关注,并将人工智能推上神坛,在于其将人工智能从幕后带到了台前。正如百度创始人李彦宏所说,人工智能正从辨别式走向生成式,AIGC成为新方向。
所谓的辨别式人工智能,指的是分辨内容跟需求匹配不匹配,主要是在辨别;生成式人工智能,指基于算法、模型、规则生成文本、图片、声音、视频、代码等内容的技术。
而科大讯飞正是在过往的辨别式人工智能领域拥有重要地位,特别是语音识别,以及语音合成、机器翻译、图文识别、图像理解、阅读理解等等众多领域。
纵观其发展历程,科大讯飞在2014年正式启动“讯飞超脑计划”,研发基于类人神经网络的认知智能系统;2022年提出讯飞超脑2030计划,进一步深耕认知智能,并承办国家语言及语言国家重点实验室等多项工作,成为AI领域的“国家队”,12月15日启动“1+N”认知大模型专项攻关,其中“1”就是指通用认知智能大模型,“N”就是大模型在教育、办公、汽车、人机交互等各个领域的落地。
可见,科大讯飞不仅在辨别式人工智能时代占据重要的一席之地,在生成式人工智能赛道也已经启程,虽然当下拿出的星火大模型不尽如人意。
科大讯飞的困境
当然,在人工智能转型的当下,并非只有百度和科大讯飞参与其中,在大模型方面,几乎国内巨头全员出击,比如百度文心一言、华为盘古、阿里巴巴通义千问、腾讯混元、商汤科技日日新等等。
另外,各路大佬也不甘人后,包括李开复、王兴、王慧文、王小川、张一鸣等等,都在摩拳擦掌。
纵使科大讯飞在语音语义相关技术方面实力雄厚,但其他企业也各有优势,比如百度的综合实力就十分强悍,包括NLP、图像识别、自动驾驶等。科大讯飞要想在后续的角力中实现突破绝非易事。
除了激烈的行业竞争外,科大讯飞的业绩表现让人担忧。
4月20日,科大讯飞发布2022年及2023年第一季度财报。
数据显示,2022年科大讯飞公司实现营收188.20亿元,同比增加2.77%;净利润5.61亿元,同比下降63.94%;扣非后净利润4.18亿元,同比下降57.31%。
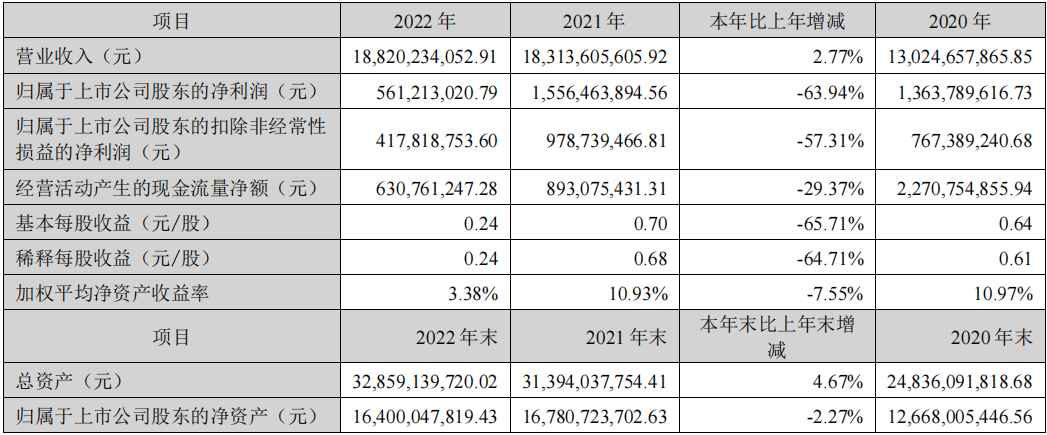
2023年第一季度,公司实现营收28.88亿元,同比下降17.64%;净亏损5789.53万元;扣非后净亏损3.38亿元。
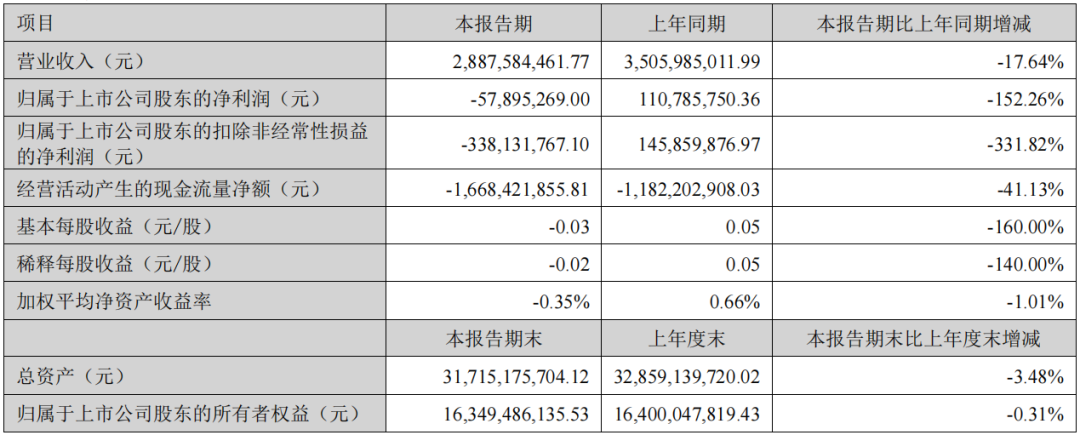
关于业绩下滑的原因,财报中提到,一方面是由于社会经济的特殊环境,另一方面是被被列入美国实体清单后,2022年被再次极限施压,从供应链到相关的合同签署需要调整的过程,也影响了当期订单签订的节奏。还有公司持股的三人行、寒武纪、商汤等金融资产因股价波动导致公允价值变动收益金额较上年同期减少 5.82 亿元等。
但与此同时我们也看到,科大讯飞的营收表现不佳原因还有很多,比如其业务占比最大的教育领域面临的激烈竞争。近年,随着学生对交互性强的AI学习机需求增大,众多企业发力,步步高、读书郎、网易有道等实力不容小觑。
另外,其他多项业务盈利能力不足,以及依赖政府补贴等问题都制约着科大讯飞的发展,这样的局面亟需一个新的机遇来扭转。而大模型,或者说星火认知大模型就是这样的一次机遇。
“星火”能否燎原?
回到讯飞星火认知大模型,在2022年12月15日,科大讯飞启动“1+N”认知大模型专项攻关,其中“1”指通用认知大模型,“N”指大模型在教育、办公、汽车、人机交互等各个领域的落地。
如今作为“1”的星火大模型已经发布,其由7大核心能力,即文本生成、语言理解、知识问答、逻辑推理、数学能力、代码能力、多模态能力。虽然其实际表现还有很多不足,但毕竟敢于让广大用户去体验,这一点是值得肯定的。
而接下来“N”的落地成为了另一个重点。
发布会上,讯飞董事长刘庆峰介绍了搭载星火大模型的一系列应用,包括教育、办公、汽车、数字员工。具体用例有星火大模型赋能的讯飞AI学习机、讯飞智能办公本、讯飞智能座舱等。
之所以说“N”是一个重点,是因为其决定着商业价值的体现,决定着其能否被市场所认可,决定着是否能够创造营收。
但同时这也考验着“1”的能力,如果这个“1”没有相当的水准,那么所谓的“N”也只能是空中楼阁。
发布会上董事长刘庆峰宣称,到8月15日,代码能力会上一个大台阶,多模态的交互能力也将正式开放。到10月24日希望星火对标ChatGPT,在中文上要超越ChatGPT,在英文上要达到跟它相当的水平。

豪言放出,但终究还是个未知数。
2021年,科大讯飞董事长刘庆峰曾提出2025年千亿营收的目标,但2022年全年营收仅188.20亿元,同比增加2.77%,2023年一季度营收更是仅有28.88亿元,同比下降17.64%。
过去千亿目标的豪言难以实现,这次又立下flag赶超ChatGPT,人们对科大讯飞的期待是否要再次落空呢?
我们期待星火在未来能够快速成长,期待了解其更多的技术内容,如果真如其所言,燎原之势便有望达成,只是从当下来看这条路充满坎坷。
毕竟大模型的研发不是抱佛脚就能实现逆袭的,需要持续的研发投入,而这对于营收困境的科大讯飞来说是一个难题。同时需要高质量训练数据集,充沛的算力资源,深度的学习框架等等。另外,在与BAT以及更多竞争对手的疯狂比拼中,科大讯飞并没有明显优势。

但总之,科大讯飞星火认知大模型的发布成为又一颗被埋下的种子,孕育着希望。


-------------------------------
10地区300亿!元宇宙产业基金释放新机遇
与元宇宙有关的七大加密货币
Solana简史:从市值5400亿到众叛亲离
五一,淄博烧烤靠谱、成都元宇宙拉胯?
解读《浙江省元宇宙产业发展2023年工作要点》

关注元力社 畅游元宇宙
合作交流
吴经理:18600365673

请让我知道你在看

代充值")





网友评论