

先做个广告:如需代注册ChatGPT或充值 GPT5会员(plus),请添加站长微信:gptchongzhi
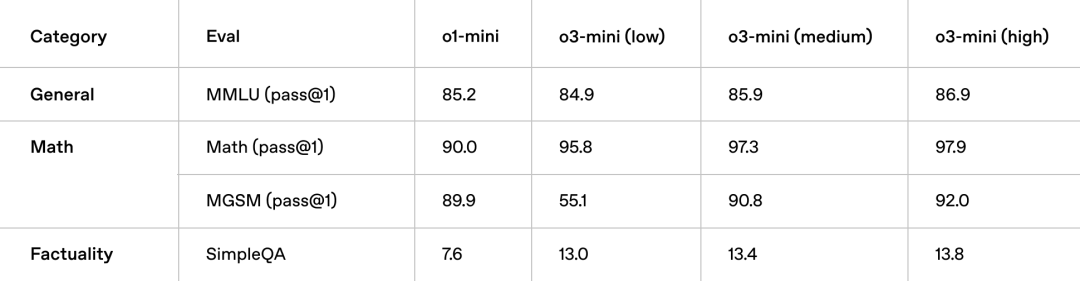
o3-mini
今天凌晨,OpenAI 发布了其最新的推理模型,o3-mini 系列。
 推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
这次发布的 o3 包含推理强度为低、中、高三个选项,目前 GPT 聊天中已可体验中等推理强度的 o3-mini 和高推理强度的 o3-mini-high 模型。
在 Humanity's Last Exam 的最新测评基准中,o3-mini-high 模型的准确率和校准误差均优于 DeepSeek R1 模型:

技术报告
与 o1 类似,o3-mini 针对 STEM 推理进行了优化:
o3 mini 对比 o1:性能相当,速度更快
在中等推理强度下,o3-mini 在数学、编程和科学方面的表现与 o1 相当,同时提供更快的响应速度。
o3-mini 在包括 AIME 和 GPQA 在内的一些最具挑战性的推理和智能评估中与 o1 的表现相当。
o3 mini 对比 o1-mini:更准确,更清晰
专家测试者的评估显示,o3-mini 比 o1-mini 能产生更准确、更清晰的答案,具有更强的推理能力。测试者在 56%的情况下更倾向于 o3-mini 的响应,并观察到在困难的现实世界问题上主要错误减少了 39%。
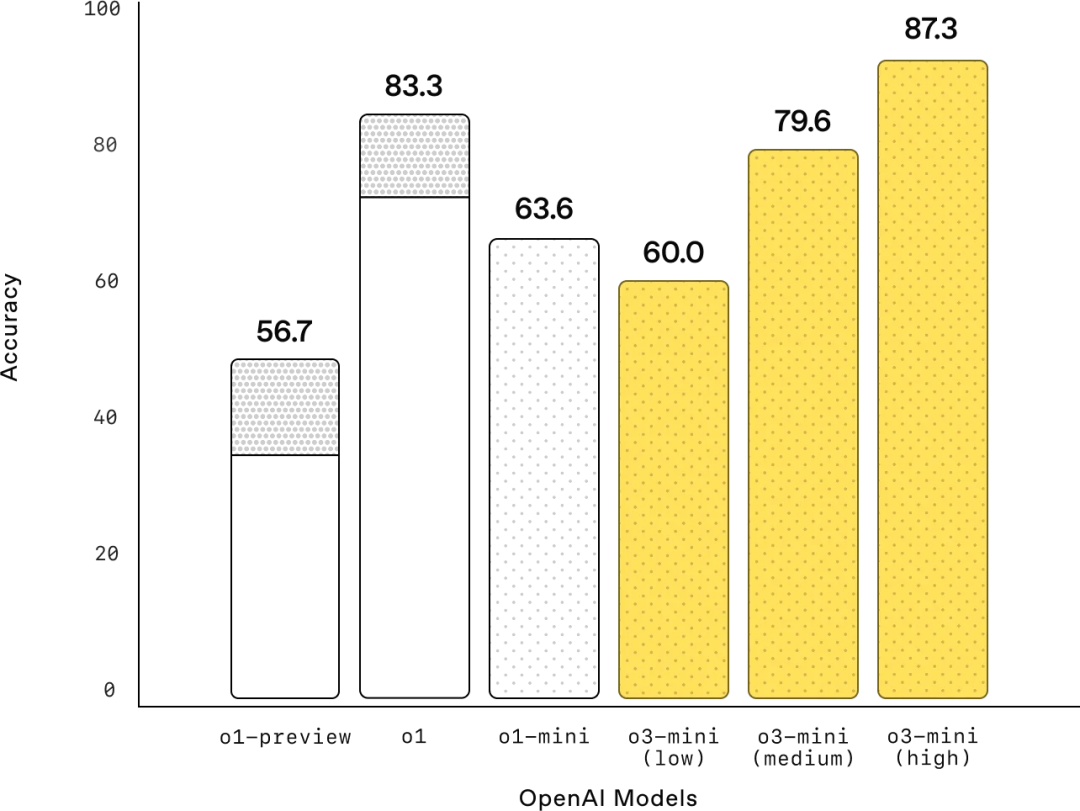
1. 数学能力
在 AIME 2024 的测试中,低推理强度的情况下,o3-mini 达到了与 o1-mini 相当的性能表现。而在中等推理强度的情况下,o3-mini 达到了与 o1 相当的性能表现。
在高推理强度的情况下,o3-mini 的表现超过了 o1-mini 和 o1 两者。

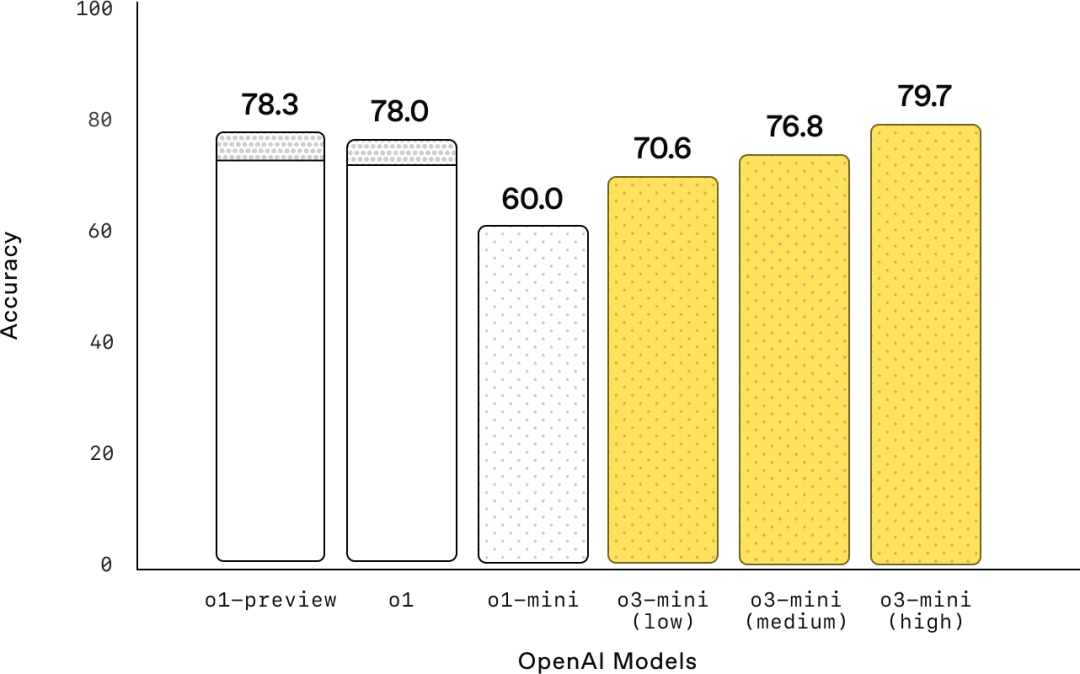
2. 科学问题
在博士级别的生物、化学和物理问题上,o3-mini 在低推理强度下表现优于 o1-mini。在高推理强度下,o3-mini 的表现与 o1 相当。
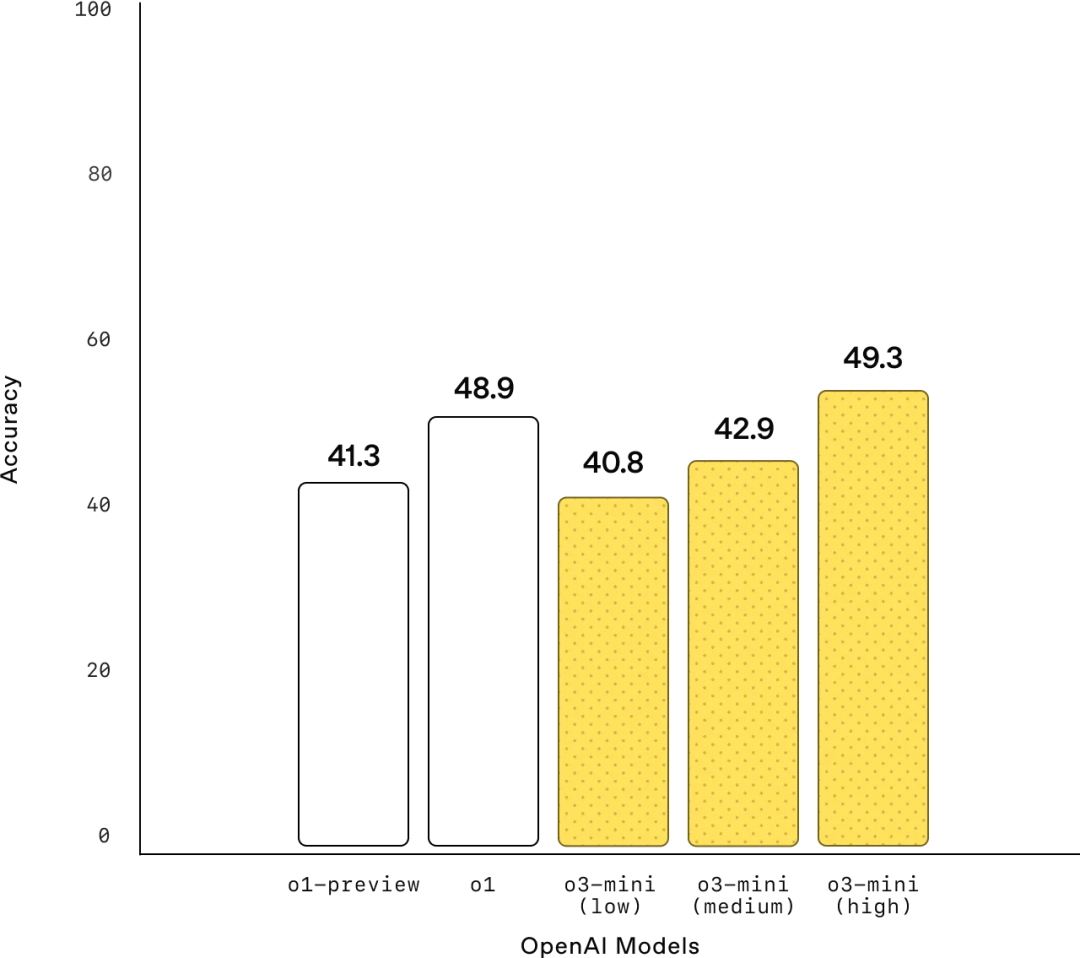
3. 编程能力
在编程的各项能力上,o3-mini-high 完全领先于 o1:
根据其在 LiveBench 的表现来看,随着推理强度升级,o3-mini的优势还在不断扩大:

4. 常识问题
o3-mini 在多个常识知识领域的评估中表现优于 o1-mini:
o3-mini-high 实测
1. 简单代码生成
用 o3-mini-high 生成一个春节主题的烟花效果,o3 一次就生成了我要的效果:

对比 DeepSeek R1,相同的提示词,R1 第一次生成的无法运行,修改两次后的效果如下:

2. 物理模拟测试
参考国外网友的 prompt 做了这样一个测试:让一个球在旋转的六边形内弹跳,球应受到重力和摩擦力的影响。
o3 一次生成结果如下:
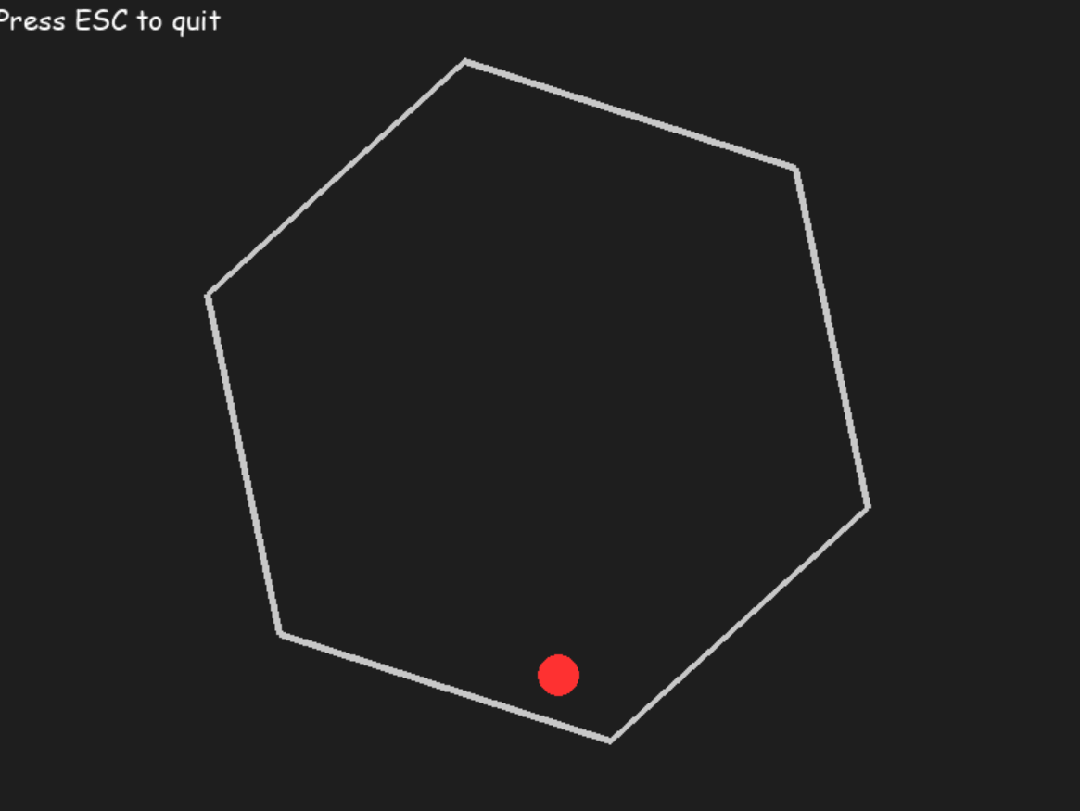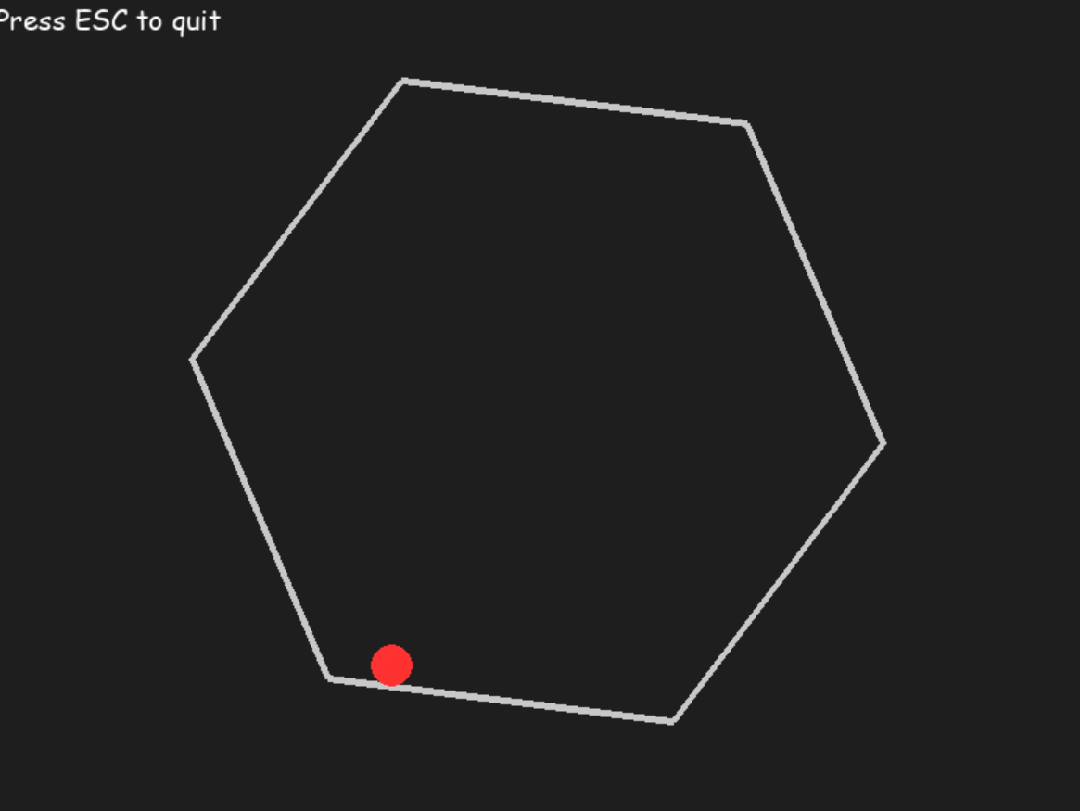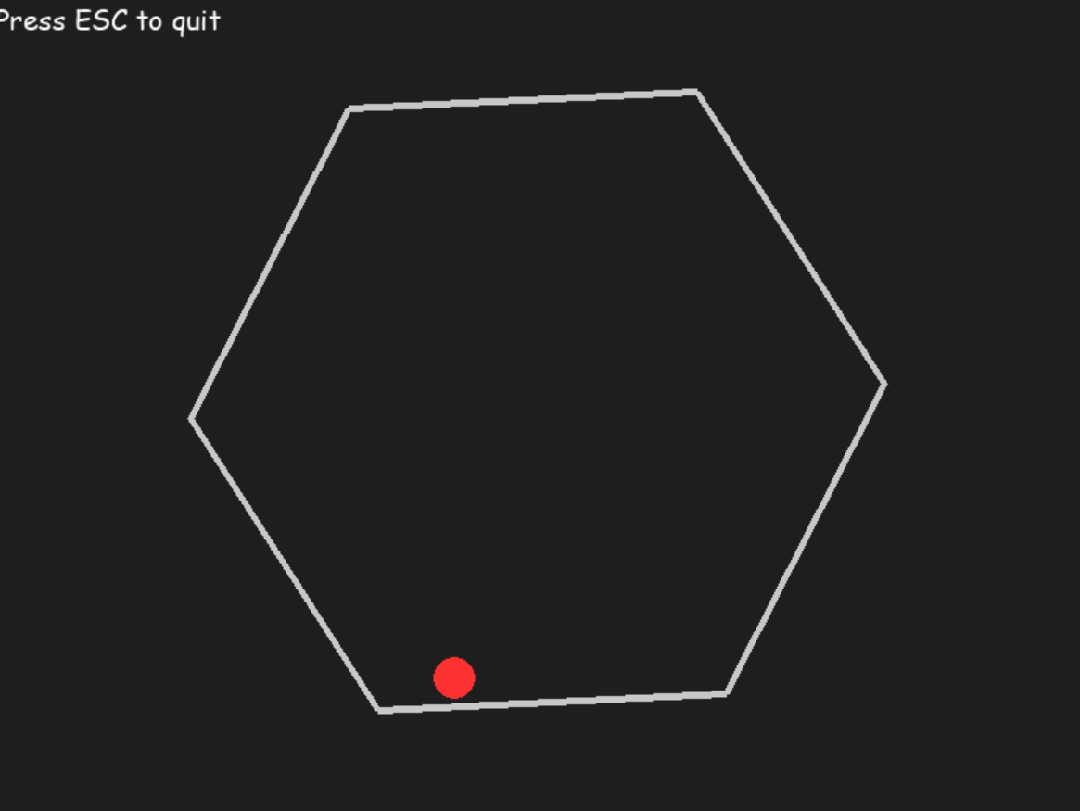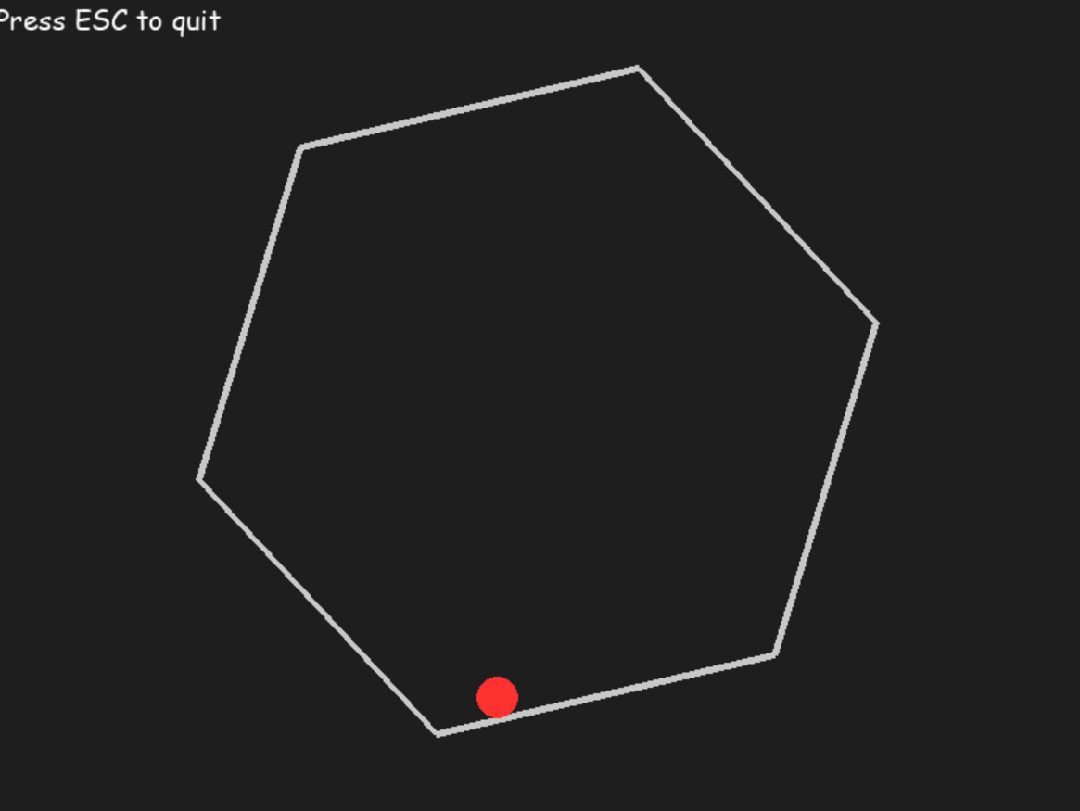
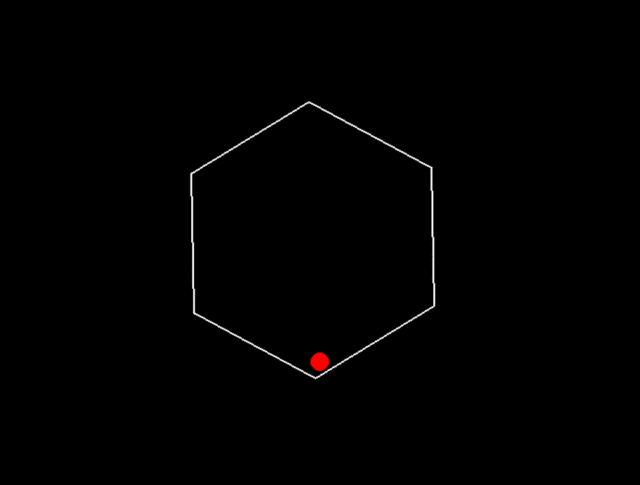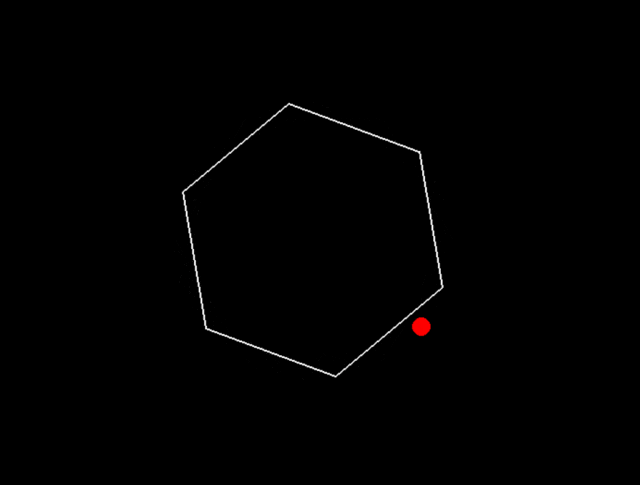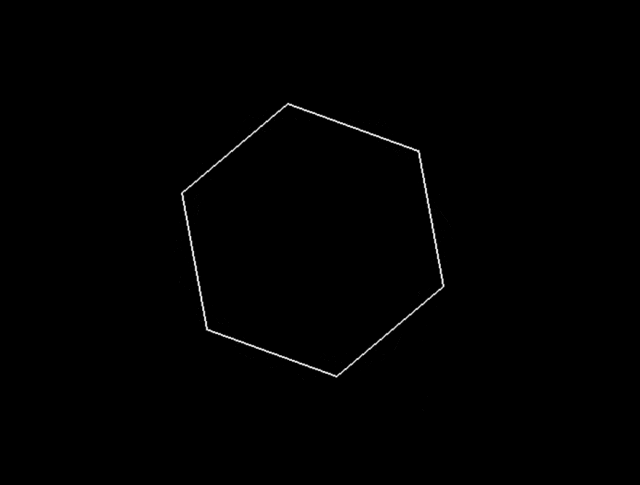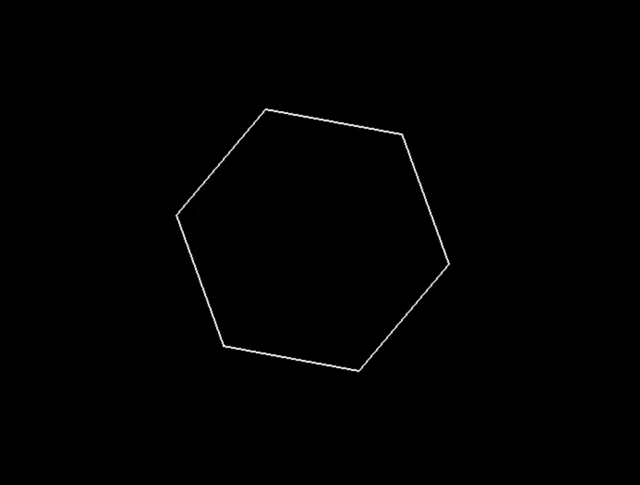
Claude3.5 Sonnet:
只一秒, Sonnet 的球居然掉了......
R1 由于 API 不稳定,无法进行测试。
接下来,使用 Python 模拟四维超立方体内弹跳球。
o3 一次生成的结果如下,完全符合物理定律,并且在代码中给出了详细的速度分量的转化公式:

Claude3.5 Sonnet 的结果,足够幽默:

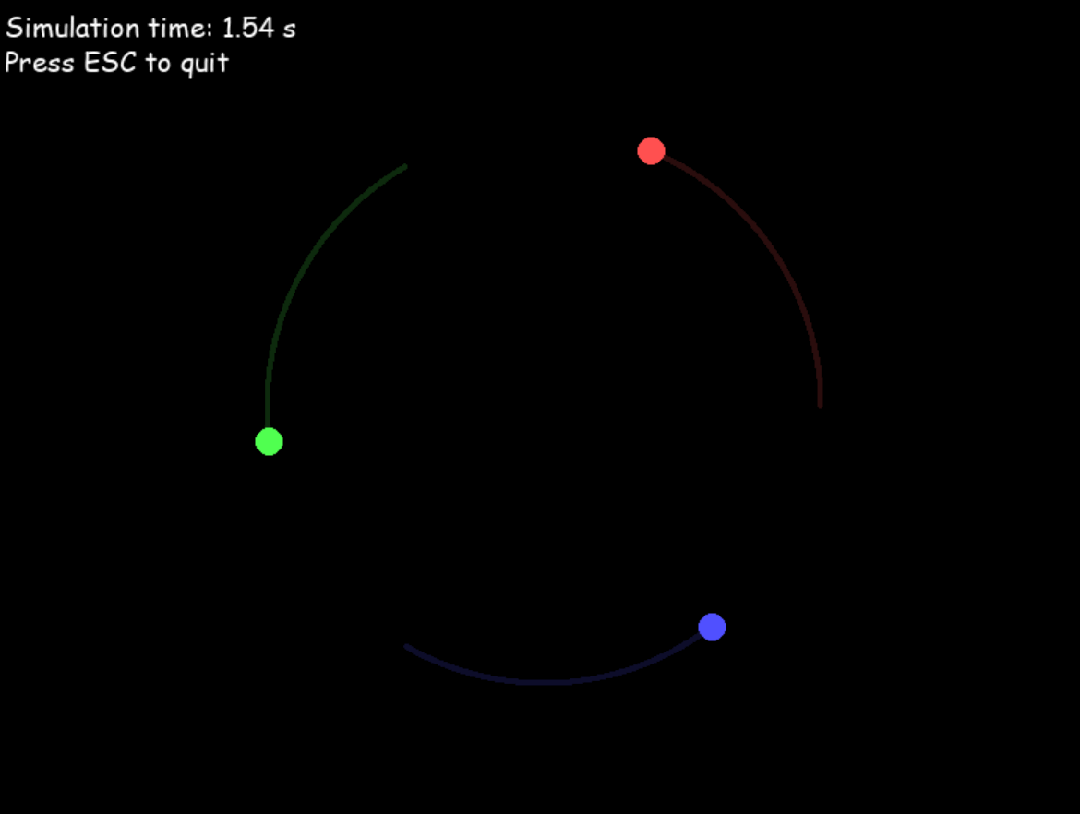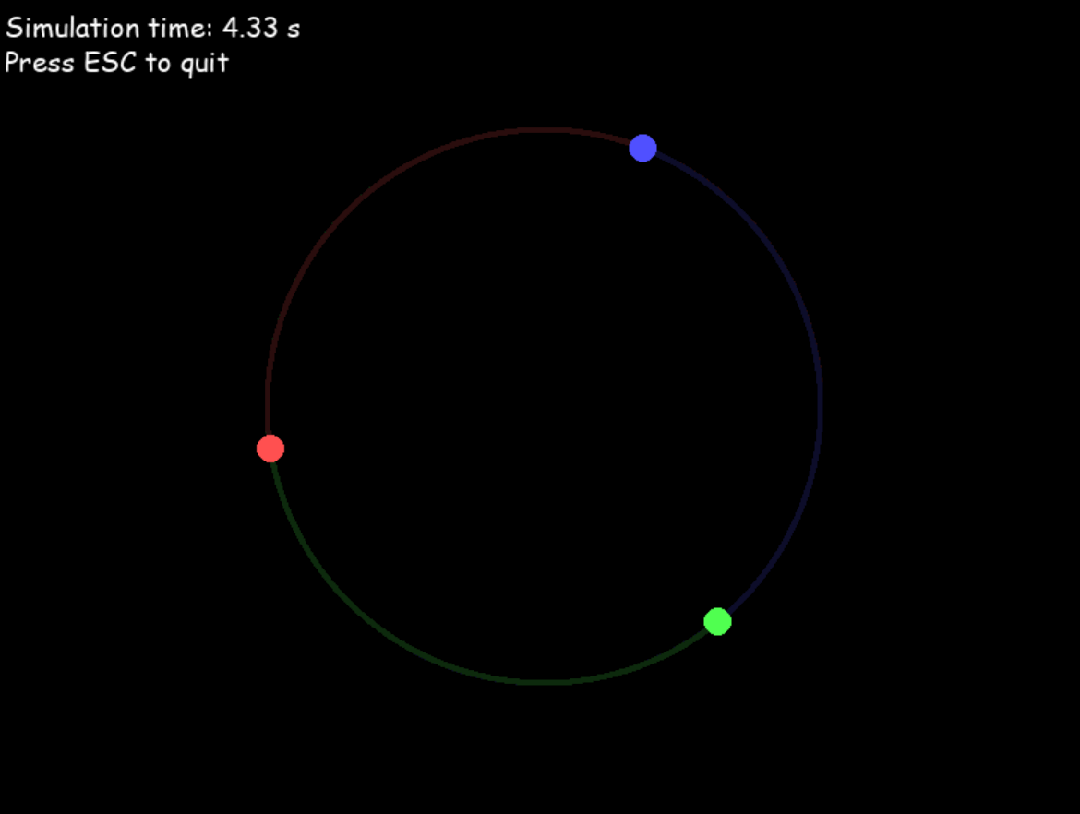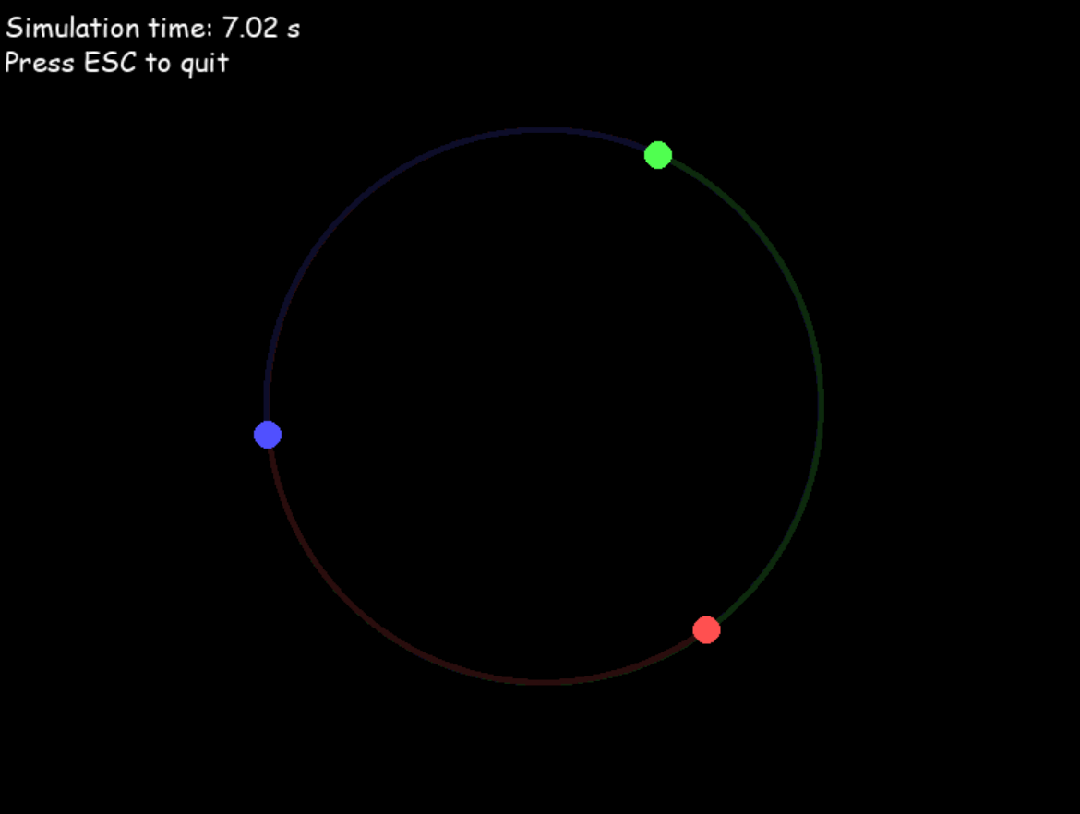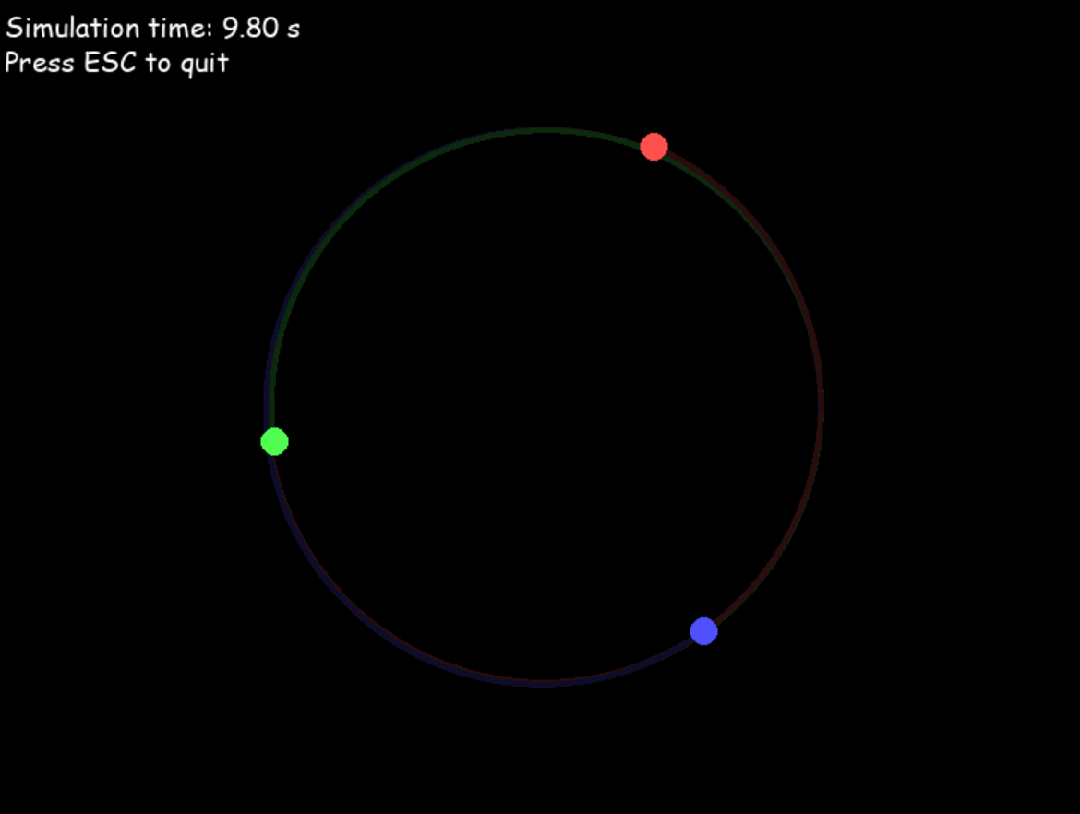
接下来,我让 o3 模拟三体运动。提示词就一句话:
写一个 python 程序,模拟三体运动,需要呈现天体运动轨迹。
o3 一次生成的结果如下,并且还告诉了我这些:





3. 俄罗斯方块
用 o3 生成一个俄罗斯方块游戏,需要有难度选择和计分板。一次出结果:
4. 科学问题
前段时间刚好看了一篇利用 RL 进行水库联合调度的文章。于是我让 o3 思考这个问题。
相比于之前的 o1 或是 DeepSeek R1,o3 思考过程结构清晰,简单明了,没有“话痨”般的反复 Reflection:






5. 数学竞赛
我在 2024 年第 40 届中国数学奥林匹克竞赛的题目中,选了这样一道题目:





结合上边的对于科学问题的测试,o3 的思考过程和结果输出,都更加“优雅”。
总结
在 DeepSeek 的追赶之下 ,o3-mini 的发布似乎是临时为之。
但 o3-mini 确实解决了 o1 、DeepSeek R1 在推理过程中那种混乱、过度反思的问题(R1 尤为严重),o3-mini 的思考过程更为精准,逻辑也更强。
实测下来,我自己的感觉是:
o3 的思考过程与结果输出有一种简洁、朴素和一致性的美。
简洁的描述代表着低复杂度、高压缩率,在理论上更接近事物的“最优”描述。
当一个 AI 能够用较少的信息有效描述和预测复杂现象时,这种精炼与高效本身就蕴含着一种独特的美感。
而最简单、最朴素的表述,往往也最能直接地反映事物的本质。
代充值")





网友评论