

先做个广告:如需代注册ChatGPT或充值 GPT5会员(plus),请添加站长微信:gptchongzhi

导读
 推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
2022年11月 ,OpenAI推出⼈工智能大语音模型—聊天机器⼈ChatGpt。
随着ChatGpt的出现 ,2023年刮起了⼀阵“AI风”。各种文章铺天盖地 ,鼓吹着AI时代的来 临 ,AIGC将席卷整个科技行业甚至是颠覆整个⼈类社会。
但你真的了解ChatGpt嘛?你可以尝试问自己几个问题:
01 ChatGpt是什么 :LLM是什么?NLP是什么?GPT是什么?BERT是什么?Transformer是什么?RLHF是什么?AGI是什么?
02 ChatGpt超能力来源是什么?是新的范式突破吗还是过往AI的延伸?
03 ChatGpt的发展过程是怎样的?现在以及未来呢?
01 行业观点
搞清楚ChatGpt是什么和它超能力的来源是什么 ,其实是⼀件很困难的事情 (毕竟基于现在看 ,ChatGpt并不可能会开源) ,况且连最顶尖的⼈工智能大佬们也没有达成共识。
比如 ,图灵奖得主Yann LeCun认为GPT家族所依赖的学习范式就是⼀个基于auto-regressive ( 自回归) 的LLM (large language model ,大语言模型) ,只是因为OpenAI 是个创业公司 ,大家宽容度较高。
他也曾在⼀场辩论中提出了“Nobody in their right mind will use autoregressive models 5 years from now” (从现在起5年内 ,没有哪个头脑正常的⼈会使用自回归模型。)‘
但同时 ,ChatGpt受到许多大佬的吹捧也是有⼈提出“此刻是属于AI界的IPhone时刻”观点 ,比如越来越多的AI大佬们决定朝着AGI(artificial general intelligence ,通用⼈工智 能)前进。
开始深入探讨之前 ,我们可以着重参考两篇综述(点击可直达原文) :
大语言模型技术精要
ChatGpt的各项超能力从哪里来
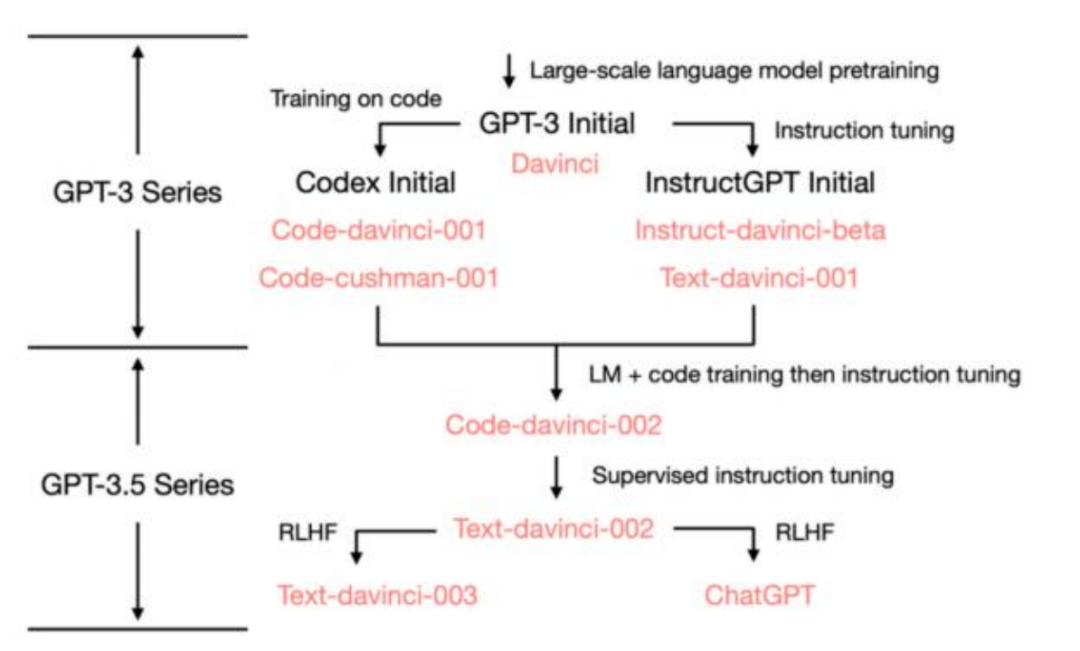
02 真正的难点
结合上面的图可以⼀起简单的梳理⼀下 :
GPT-3Initial :通过超大量的语言模型进行预训练 ,已经成了⼀个非常令⼈惊艳的 LLM ,但最多也只能说是引起了量变。
Codex Initial和InstructGPT Initial :通过阅读代码和InstructGPT的模式 ,训练出了两 款新的模型。
GPT3.5 :在这个阶段其实已经涌现了“乌鸦”能力 ,产生了质变。其实“乌鸦”能力的涌 现就可以看作是新的范式突破 (下文会详细介绍) 。但此时 ,可能并不适合⼈类使 用。
ChatGpt :在通过RLHF ( Reinforcement Learning Human Feedback ,基于⼈类反馈 对语言模型进行强化学习) 的帮助下和监管下的指令微调 ,找到了合适⼈类自然语言 的GPT应用 ,也更加符合了“Chat”这⼀特性。
其实我们就可以明白 ,真正厉害的模型是GPT-3.5 ,而ChatGPT只是⼀个厉害的应用方式。
应用方式容易复制 ,聊天机器⼈⼗年前就已经出现的应用 ,RLHF难度其实也不大 , 就连微软最近也是开源了“DeepSpeed Chat”这款炼丹神器 (用于各种规模的ChatGPT类 模型的简单、快速且经济的RLHF训练) 。
真正的难点是什么呢?是上面提到的“乌鸦”能力 的复现。
除了OpenAI公司 ,可能根本没有⼈知道它是如何涌现的 ,是随着数据量的不断 扩充还是数据质量的不断提高还是模型大小的不断提升?但这些都是猜想 ,这⼀个观点其实也更加证明了OpenAI是不可能开源的。
所以这很有可能不是通过烧几万张显卡或是GPU就能实现的 ,说不定投入即使够多但仍有可能是打了水漂。
也正是因为这⼀优势,足以使OpenAI公司与其他各家公司拉开好几年的发展优势 ;反观国内的各家公司 ,也许同样只是“东施效颦” ,在没有“乌鸦”能力的LLM模型上套了⼀个与ChatGPT的应用方式。
03 理解新范式—乌鸦
下面 ,我们首先简单的介绍下什么叫ChatGPT所属于的可能的新范式—乌鸦
对于⼈工智能 ,朱松纯教授以“鹦鹉”和“乌鸦”为例 ,进行了⼈工智能范式的区分 :
“鹦鹉范式”的⼈工智能 ,就是学界目前普遍认定的大数据+大算力+深度学习, 这包括当前的大型预训练模式。
机器学习 ,包括深度学习 ,所遵循的都属于这种范式“data fitting”。我们通常会把机器学习、 自然语言处理的数据、模型的输出称为向量数据。具体来说就是数据之间大概也可以用我们数学上的函数类似于Y=F (X) 来推导 ,给定⼀些X和结果Y ,机器学习寻找出X和Y⼀定的对应关系 ,优化成⼀个特定的方程。
因此 ,即使碰到⼀个未知的X ,也可以按照规律推导出Y的最佳目标。
但这其中有⼀个弊端 ,就像是我们的方程会有限制条件 ,类似于我的X因素只能输入数字 ,不能输入字母。
在现实中的例子就是我训练的因子的范围只是动物 类图片,但你给了我⼀张建筑类的图片 ,输出的结果肯定是会差强⼈意的。
这就很想鹦鹉学舌的机制 ,鹦鹉不管你输出内容的真实意义 ,只是通过自己的方式理解了这个发音 ,并且模仿了出来。
04 举例 :推荐算法的原理
现有算法的主要做法是 (抖音举例):
把每个视频抽象成特征。
把每个⼈抽象成特征。
通过特征之间的泛化来互相匹配。
如果用实际例子来理解就是 :
年轻男性A用户喜欢看女主播变装视频 ( 内容+画像推荐)
你的“朋友们”点赞过该类型视频。( 关系链)
跟你有着⼀样画像的⼈ ,除了喜欢看变装 视频还喜欢看女主播唱歌。
因此属于这种范式的NLP处理过程 ,必须首先设定好具体的任务 ,规划好如何把数据之间形成固定的function ,以及function如何调用相应的能力。
“乌鸦范式” ,则是⼀种“小数据、大任务”的模式。

摄影师曾在日本拍摄到⼀只没有受过⼈类训练的野生乌鸦—— 它来到城市自己生活 ,需要寻觅食物。 当它找到⼀个坚果时 ,只凭借自己的力量无论如何也打不开它 ,哪怕从高空扔下去也砸不开。
但随后它发现:如果把坚果放在马路中间 ,坚果 便能够被路过的车辆碾压开。但路上车来车往 ,对自身安全威胁太大 。
观望了⼀阵后它最终发现 :把坚果扔到斑马线上 ,让车辆压开坚果,自己只需在⼀旁的电线杆处等待红灯亮起、车辆都停下时 ,再大摇大摆地下去吃掉坚果即可。
总结⼀下 :乌鸦通过观,自主串通了 :
汽车能压碎坚果。
车对自身安全威胁较大。
红绿灯能够控制车辆通行。其实就是在做inferencing这件事。
05 ChatGPT拥有乌鸦能力的证据
LLM模型是否真的拥有“达成inference”的能力并不像图灵测试 ,他没有⼀个具体的标准衡量。我们也可以从下面几点感受出,他是否真的具有这样的能力。
01 ChatGPT拥有in-context correction的能力 (结合上下文的能力)
即使如果说错了 ,他也能对自己进行矫正 ,也能听懂用户所描述的错误 ,并以正确的方向或是 用户所要求的方向进行修正。毕竟correction的能力比learning的能力难多得多
02 描述的越详细ChatGPT反而回答得更好。
我们可以想⼀想 ,描述的越具体或者更精细如果是通过“鹦鹉学舌”的逻辑 ,预训练的文本里应越难匹配到。
03 在询问ChatGPT互联网上搜索不到的内容时 ,也能给出不错的答案。
04 ChatGPT能通过信息猜你心中的想法 (不知道大家有没有刷到过⼀条关于让 ChatGPT扮演自己母亲的视频) 。
05 你可以给ChatGPT设立独特的规则 ,并且它能够完美理解你的规则且不出差错的利用规则。
可以对比过往的NLP ( 自然语言处理) 模型范式是否能够达到类似效果。
当然可以 ,但它有个前提 ,过往的模型你需要针对具体的问题进行具体的设计 ,且只要你说的话不够结构 化 ,模型的表现就很难保证 ,更别说在模型预训练的资料库中没有出现过的问题了。
ChatGPT是⼀个“开窍”之后拥有理解能力的人 ,从而带来了举⼀反三的 能力,逻辑推演的能力,知错就改的能力。
过往ML :需要“喂” ,之后“模仿” ,基于的是“对应关系”
ChatGPT :需要“教” ,之后“懂” ,基于的是“内在逻辑”
后者的能力上限 ,可能也是为何引起业界既兴奋⼜焦虑的原因之⼀吧。
06 发展预测
ChatGPT后几年的发展可能是什么?
ChatGPT4也已经发布了⼀段时间了 ,其中更新的亮点包括 :GPT-4模型可以对图片进行理解以及增加了ChatGPT4结合插件的功能。
GPT-4模型相比GPT-3模型 ,模型参数⼜大了多少 ,我们不得而知。
但值得肯定的是,往多模态的方向发展。
目前已经推出了支持图片的输入 (虽然目前即使是升级了plus的用户 ,也并没有看到上传图片的入⼝) ,GPT-4模型已经不再是以前的瞎子了 ,对世界的丰富多彩只能靠别⼈的转述来想象。
现在它似乎已经拥有了视觉 ,就像OpenAI团队演示的视频⼀样 :给他⼀张小男孩拿着⼀个即将飞上空中的气球图片 ,问他剪断线之后 ,可能会发生什么?
GPT-4能够正确推理出结果 ,气球将会飞入空中 ,这也更加验证了我们上文所说的具有inference的能力。
07 ChatGPT Wrapper
上文提到的第⼆点 ,结合了插件的功能。
从此以往 ,ChatGPT不仅可以打开此前不能联网的限制 ,而且也许能够更好地服务我们平常⼈的日常需求。
结合目前的AIGC技术 ,AI可以跟你聊天、画画、 写作、作曲、作视频等等 ;而我们希望AI干的事情可能是买东西、叫外卖、各种麻烦⼜费时间的 事情。
因此,我们现在可以相信ChatGPT已经进⼊了第⼆阶段的应⽤⽅式。
现在属于是将ChatGPT的能⼒,包装成某种具体的解决⽅案。
ChatGPT结合New Bing就是很好的例⼦:
此前社交媒体⽹络上已经疯传New Bing将在下⼀次迭代结合进ChatGPT,关是相关消息⼀出,就已经让Google市值蒸发上亿美元,真正问世,可⻅⼜是⼀次不⼩的打击。
以及⽹络上出现的传闻,ChatGPT将杀向“office suite”,此后的办公⽂档软件使⽤更加便捷。(与我们⾃⼰提出的Cyber Excel概念类似)
显⽽易⻅,ChatGPT的通⽤性,万⾦油,能够保证他能和任何第三⽅应⽤完美结合。
那有没有可能以ChatGPT为底座,从零到⼀来打造呢?
再举个例⼦,假设抖⾳希望通过ChatGPT来优化下⼀代的短视频推荐算法,如何才能做到呢?
第⼀,ChatGPT需要能够调⽤抖⾳的数据;
第⼆,ChatGPT能够修改抖⾳的数据与参数。
⽬前在现有已成熟的框架下,哪怕对于ChatGPT来说恐怕也难以实现,因为你需要⼀个对系统和数据⾜够理解的⼈来教给ChatGPT,他才能通过推理进⾏优化。
但我们如果幻想从⼀开始ChatGPT就从头全程参与了数据建模和系统建设,那对于他来说,改进也就容易多了。所有我们可以⼤胆推测,以后各种软件⼯程⼀⽅⾯需要去适配ChatGPT,⼀⽅⾯也可能会⾯临收到ChatGPT的挑战。
08 TO C的转变
随着越来越多的⼤佬开始朝着AGI⽅向涌⼊,说不定也已经说明了未来之后的趋势。
ChatGPT可能会⾛向个⼈化,成为个⼈版ChatGPT。
就在不久之前,全球最⼤的开源对话数据集OpenAssistant Conversation发布,况且Hugging Face上还有很多可以使⽤的⼤
型数据集。(也许通过市⾯上已有的数据集训练模型,反推得到我们想要的数据集也是⼀
个不错的思路。)
因此,市⾯上也已经有了⼀套不错的组合拳打法:
DeepSpeed
Chat+数据集,每个⼈都可以打造属于⾃⼰的类ChatGPT模型且价格实惠。
我们预测会进⼀步向着这个⽅向加强,同样也是因为有⼏个明显的商业优点:
⼤家可以调教专属于⾃⼰的ChatGPT,跟它⻓时间的聊天,它不仅能够适配你的喜好,也能达成专属于你们的默契。
我们不得不承认ChatGPT已经赢在了起跑线上,如果还杀向同样的赛道不就是⾃寻死路嘛。我们能做的,也有可能是OpenAI公司后续要做的,打造垂类赛道。
想象如下场景,假如你是⼀名优秀的营销经理,假以时⽇,你的ChatGPT的营销能⼒,应该已经可以吊打其他ChatGPT的营销能⼒,专攻于某⼀⽅向,但若真的到了那⼀刻,可能也就离⼈类解放⽣产⼒的未来不远了。
09 Fine-tunning ——微调
讲到这⾥我们也可以科普下Fine tunning和Embedding的区别
Fine-tunning ⼀般称之为微调。
GPT-4已经预训练了⼤量的互联⽹内容,只需要在prompt⾥写了少量的⽤例,他基本可以感知你的⽤意,并⽣成⼀段基本合理的符合你预期的结果。这个功能⼀般叫做“few-shot learning”。
Fine-tunning就是基于few-shot learning,通过训练⽐写在prompt⾥更多的⽰例,可以得到更好的结果。被模型微调后,就不⽤在prompt⾥再写⼀些实例了。从⽽达到节省成本和耗时的效果。
⽐如不进⾏ fine-tune 提问
prompt:
⼩红喜欢洋娃娃。⼩红的性别是?
completion:
⼥孩,所以她很喜欢洋娃娃。洋娃娃通常有着丰富多彩的服装和装饰,可以让⼩红玩得很开⼼。此外,红还可以给洋娃娃起名
字,造出⼀个属于⾃⼰的⼩世界,从⽽获得更多的乐趣。
在 prompt ⾥加⼊⽰例
prompt:
⽰例:⼩红喜欢洋娃娃。⼩红的性别是?
答案:⼥
经过提⽰的 prompt 会按照⽰例的格式回答你的问题。
prompt:
⼩红喜欢裙⼦。⼩红的性别是?
completion:
答案: ⼥
10 Embedding——嵌⼊
Embedding⼀般称之为嵌⼊。
embedding ⼀般是指将⼀个内容实体映射为低维向量,从⽽可以获得内容之间的相似度。OpenAI 的 embedding 是计算⽂本与维度的相关性,默认的 ada-002 模型会将⽂本解析为 1536 个维度。⽤户可以通过⽂本之间的 embedding 计算相似
度。
embedding 的使⽤场景是可以根据⽤户提供的语料⽚段与 prompt 内容计算相关度,然后将最相关的语料⽚段作为上下⽂放prompt 中,以提⾼ completion 的准确率。
简单的你可以理解成,Embedding更像是封装了⼀层索引。
例:
我有⼀堆语料,想让 GPT-3 依据我的语料输出内容 - 使⽤ embedding
可以根据产品的使⽤⼿册来回答⽤户的问题- 使⽤ embedding
希望⽤户按照⼀定格式提交问题 - 使⽤ fine-tunning
想让 GPT-3 模仿⼀个温柔贤惠的⼥⼈和我对话 - 使⽤ fine-tunning
11 总结
ChatGPT的范式突破是“乌鸦”能⼒,它具有理解甚⾄推理的能⼒,⽽作为对⽐,过往ML的能⼒模式是“鹦鹉”能⼒,所做的只是通过固定规律寻找对应关系。
为什么是OpenAI作出了ChatGPT,⽽不是其他机构呢?我们也可以做个简单分析。
⼀点是OpenAI对LLM的理念,他们从⼀开始就视通往AGI为最终⽬标。
在他们的眼中,未来的AGI就应该是这样:有⼀个超⼤的LLM模型,⾜以从模型的海量数据中学习各种知识,并能通过它来解决各种各样的实际问题,⽽且他应该能够理解⼈类的指令,以便于⼈类使⽤。
他们并没有因为Bert的出现和爆⽕⽽放弃⾃⼰原来的线路切换⾄双向语⾔模型,仍然⾛⽂本⽣成的路,⽽且开始尝试零⽰例(zero shot)prompt和少量⽰例(few shot)prompt,虽然也⼩有成就,但只是被Bert+fine-tuning的光明所覆盖。
直⾄,我们上⽂提到的,不知何时涌现的“乌鸦”的能⼒,才有了GPT3.0的出现。
在当下,我们应该拥抱变化,学会通过⾃然语⾔调⽤ChatGPT,做好他的项⽬经理,才能更好的把握未来。
最后回答我们的第⼀个问题:
LLM,Large Language Model,⼤型语⾔模型。基于⼤型语⾔模型的实现,演进出了最主流的两个⽅向,即Bert和GPT,两个最主要的差别:
Bert,双向,预训练语⾔模型+fine-tunning。
GPT,⾃回归,预训练语⾔模型+Prompting。
Transformer则是GPT和BERT的前⾝,被⽤于处理NLP(⾃然语⾔模型)。
RLHF则是Reinforcement Learningfrom Human Feedback,GPT3.0模型就是⼀款通过GPT⽅式训练后再经过RLHF打造成更适合⼈类使⽤的⼀款⼤语⾔模型,并体现了NLP技术的实现,最终希望变成⼀款⼈们⼼仪的AGI⼯具。(Artificial general intelligence)

代充值")





网友评论