

先做个广告:如需代注册ChatGPT或充值 GPT5会员(plus),请添加站长微信:gptchongzhi
ChatGPT/GPT-4做知识图谱构建推理怎么样?
 推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top

这篇论文对大型语言模型(LLMs)在知识图谱(KG)构建和推理中的作用进行了详尽的定量和定性评估。我们使用了八个不同的数据集,涵盖了实体、关系和事件提取,链接预测,和问题回答等方面。实证上,我们的发现表明,GPT-4在大多数任务中表现优于ChatGPT,甚至在某些推理和问题回答的数据集中超过了微调模型。此外,我们的综述还扩展到了LLMs在信息提取方面的潜在泛化能力,这在虚拟知识提取任务的介绍和VINE数据集的开发中达到了高潮。依据这些实证发现,我们进一步提出了AutoKG,这是一种使用LLMs进行KG构建和推理的多智能体方法,旨在勾画出这个领域的未来并提供激动人心的进步机会。我们期待我们的研究能为未来的KG的实践提供宝贵的见解。
https://www.zhuanzhi.ai/paper/1eaf180a074880561801fc30abd787ba
1. 引言
知识图谱(KG)是一个由实体、概念和关系组成的语义网络(Cai et al., 2022;Chen et al., 2023;Zhu et al., 2022;Liang et al., 2022),它可以催化各种场景的应用,如推荐系统、搜索引擎和问题回答系统(Zhang et al., 2021)。通常,KG构建(Ye et al., 2022b)包括几个任务,包括命名实体识别(NER)(Chiu和Nichols,2016),关系提取(RE)(Zeng et al., 2015;Chen et al., 2022),事件提取(EE)(Chen et al., 2015;Deng et al., 2020),和实体链接(EL)(Shen et al., 2015)。另一方面,KG推理,通常被称为链接预测(LP),在理解这些构建的KG中起着关键的作用(Zhang et al., 2018;Rossi et al., 2021)。此外,KG可以被用于问题回答(QA)任务(Karpukhin et al., 2020;Zhu et al., 2021),通过对与问题相关的关系子图的推理。
早期,知识图谱的构建和推理主要依赖于监督学习方法。然而,近年来,随着大型语言模型(LLMs)的显著进步,研究人员已经注意到它们在自然语言处理(NLP)领域的卓越能力。尽管有许多关于LLMs的研究(Liu et al., 2023;Shakarian et al., 2023;Lai et al., 2023),但在知识图谱领域系统地探索它们的应用仍然有限。为了解决这个问题,我们的工作研究了LLMs(如ChatGPT和GPT-4,OpenAI,2023)在知识图谱构建、知识图谱推理任务中的潜在应用性。通过理解LLMs的基本能力,我们的研究进一步深入了解了该领域的潜在未来方向。
具体来说,如图1所示,我们首先调研了LLMs在实体、关系和事件提取,链接预测,和问题回答方面的零样本和一次样本性能,以评估它们在知识图谱领域的潜在应用。实证发现表明,尽管LLMs在知识图谱构建任务中的性能有所提升,但仍落后于最先进的(SOTA)模型。然而,LLMs在推理和问题回答任务中表现出相对优越的性能。这表明它们擅长处理复杂问题,理解上下文关系,并利用预训练过程中获取的知识。因此,像GPT-4这样的LLMs作为少次信息提取器的效果有限,但作为推理助手的熟练程度相当高。为了进一步研究LLMs在信息提取任务上的表现,我们设计了一个新的任务,称为“虚拟知识提取”。这个任务旨在判断性能的观察到的改进是来自LLMs内在的广泛知识库,还是来自于指导调整和人类反馈的强化学习(RLHF)(Christiano et al., 2017)所促进的强大泛化能力。在新建的VINE数据集上的实验结果表明,像GPT-4这样的LLMs可以迅速从指令中获取新的知识,并有效地完成相关的提取任务。
在这些实证发现中,我们认为LLMs对指令的极大依赖使得为知识图谱的构建和推理设计合适的提示变得费时费力。为了促进进一步的研究,我们引入了AutoKG的概念,它使用多个LLMs的代理自动进行知识图谱的构建和推理。总的来说,我们的研究做出了以下贡献:
我们评估了LLMs,包括GPT-3.5, ChatGPT, GPT-4,通过在八个基准数据集上评估它们在知识图谱构建和推理的零样本和一样本性能,提供了对它们能力的初步理解。
我们设计了一个新的虚拟知识提取任务,并构建了VINE数据集。通过评估LLMs在这个数据集上的性能,我们进一步展示了像GPT-4这样的LLMs具有强大的泛化能力。
我们引入了使用交际代理自动进行知识图谱构建和推理的概念,称为AutoKG。利用LLMs的知识库,我们使多个LLMs的代理能够通过迭代对话协助知识图谱的构建和推理过程,为未来的研究提供了新的洞察。
LLMs在知识图谱构建和推理方面的新能力
最近,LLMs的出现给NLP领域注入了活力。为了探索LLMs在知识图谱领域的潜在应用,我们选择了代表性的模型,即ChatGPT和GPT-4。我们在知识图谱构建和推理领域的八个不同数据集上对它们的性能进行了全面评估。
2.1 评估原则
在这项研究中,我们对LLMs在各种知识图谱相关任务上进行了系统评估。首先,我们评估了这些模型在zero-shot和one-shotNLP任务中的能力。我们的主要目标是在面对有限数据时检查它们的泛化能力,以及在没有示范的情况下使用预训练知识有效推理的能力。其次,根据评估结果,我们对导致模型在不同任务中表现不同的因素进行了全面分析。我们旨在探究它们在某些任务中表现优越的原因和潜在缺陷。通过比较和总结这些模型的优点和限制,我们希望提供可能指导未来改进的洞察。

2.2 知识图谱的构建和推理
2.2.1 设置
实体、关系和事件提取。DuIE2.0 (Li et al., 2019)代表了业界最大的基于模式的中文关系提取数据集,包括超过210,000个中文句子和48个预定义的关系类别。SciERC (Luan et al., 2018)是一组注释了七种关系的科学摘要。Re-TACRED (Stoica et al., 2021)是TACRED关系提取数据集的显著改进版本,包含超过91,000个分布在40个关系中的句子。MAVEN (Wang et al., 2020)是一个包含4,480份文件和168种事件类型的通用领域事件提取基准。
链接预测 FB15K-237 (Toutanova et al., 2015)广泛用作评估知识图谱嵌入模型在链接预测上的性能的基准,包括237个关系和14,541个实体。ATOMIC 2020 (Hwang et al., 2021a)是一个全面的常识仓库,包含关于实体和事件的133万条推理知识元组。
问答 FreebaseQA (Jiang et al., 2019)是一个基于Freebase知识图谱构建的开放领域QA数据集,专为知识图谱QA任务设计。这个数据集包括从各种来源(如TriviaQA数据集等)收集的问题-答案对。MetaQA (Zhang et al., 2018)数据集,从WikiMovies (Miller et al., 2016)数据集扩展,提供了大量的单跳和多跳问题-答案对,总数超过400,000个。
2.2.2 总体结果
实体和关系提取 我们在SciERC, Re-TACRED, 和DuIE2.0上进行实验,每个实验涉及到测试/验证集的20个样本,并使用标准的micro F1分数进行评估。在此我们分别在每个数据集上使用PaddleNLP LIC2021 IE2,PL-Marker (Ye et al., 2022a)和EXOBRAIN (Park and Kim, 2021)作为基线。如表1所示,GPT-4在这些学术基准提取数据集上无论是zero-shot还是one-shot都取得了相对良好的性能。与ChatGPT相比,它也有所进步,尽管其性能还没有超过完全监督的小模型。
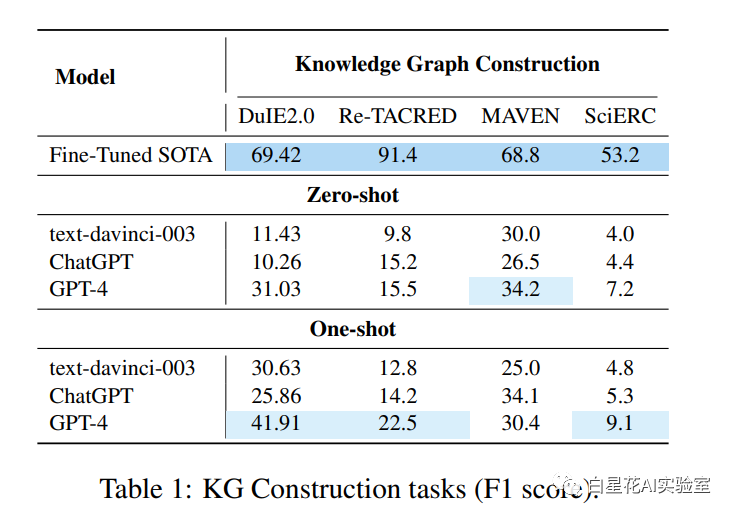
事件提取 我们在MAVEN数据集的20个随机样本上进行事件检测的实验。此外,我们使用Wang等人(2022a)的研究作为先前经过微调的SOTA。同时,即使没有演示,GPT-4也已经取得了值得称赞的结果。在这里,我们使用F-分数作为评估指标。
链接预测任务 链接预测任务包括在两个不同的数据集FB15k-237和ATOMIC2020上进行的实验。前者是包含25个实例的随机样本集,而后者包含23个代表所有可能关系的实例。在各种方法中,最好的微调模型是FB15k-237的C-LMKE (BERT-base) (Wang et al., 2022c)和ATOMIC2020的COMET (BART) (Hwang et al., 2021b)。
问题回答 我们在两个广泛使用的知识库问题回答数据集上进行评估:FreebaseQA和MetaQA。我们从每个数据集中随机抽取20个实例。对于MetaQA,由于它由不同跳数的问题组成,我们根据它们在数据集中的比例进行抽样。我们用于两个数据集的评估指标是AnswerExactMatch。
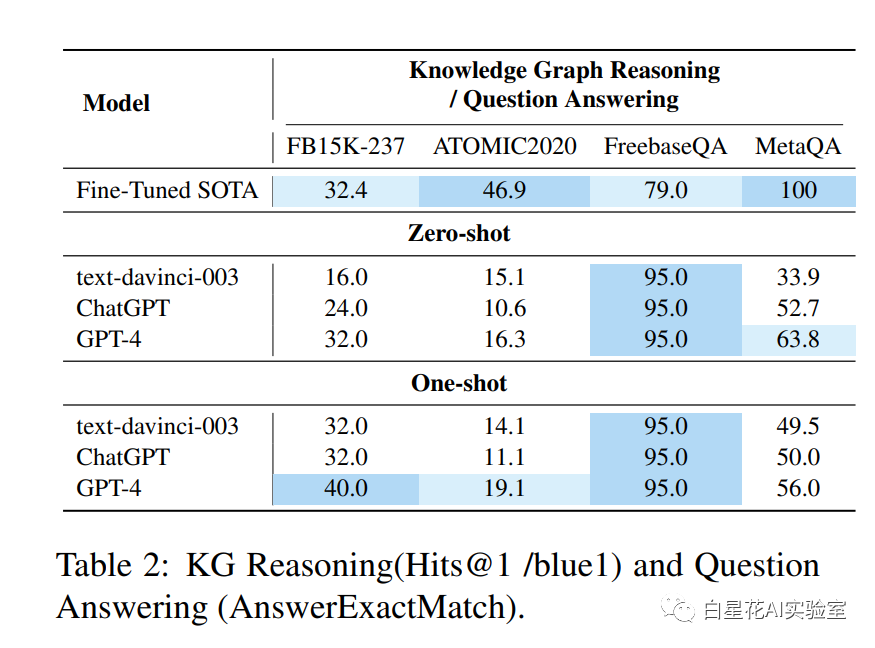
在涵盖知识图谱构建和知识图谱推理的实验中,大型语言模型(LLMs)通常在推理能力上表现优于它们的构建能力。对于知识图谱的构建任务,无论是在 zero-shot 或 one-shot 的情况下,LLMs的表现都没有超过当前最先进模型的表现。这与之前在信息提取任务上进行的实验(Ma等人,2023)保持一致,这些实验表明,大型语言模型通常并不擅长进行少样本的信息提取。相反,在知识图谱推理任务中,所有LLMs在one-shot设置中,以及GPT-4在zero-shot设置中,都达到了最先进(SOTA)的表现。这些发现为增强我们对大型模型的性能和它们在知识图谱领域内的适应性的理解提供了有意义的见解。我们提出了对这种现象的几种可能解释:首先,知识图谱构建任务包括识别和提取实体、关系、事件等,使得它比推理任务更为复杂。相反,推理任务,以链接预测为典型,主要依赖于已有的实体和关系进行推断,使得任务相对直接。其次,我们推测LLMs在推理任务中表现优异可能归因于它们在预训练阶段接触到的相关知识。
3 未来机遇:自动化知识图谱构建和推理
最近,大型语言模型(LLMs)引起了相当大的关注,并在各种复杂任务中展示了精通的能力。然而,像ChatGPT这样的技术的成功,仍然主要依赖于大量的人力输入,以引导对话文本的生成。随着用户逐步精细化任务描述和要求,并与ChatGPT建立对话环境,模型能够提供越来越精确、高质量的回应。然而,从模型开发的角度看,这个过程仍然是劳动密集型和耗时的。因此,研究人员已经开始研究使大型模型能够自主生成指导文本的可能性。例如,AutoGPT可以独立生成提示,并执行像事件分析、营销计划创建、编程和数学操作等任务。同时,Li等人(2023)深入研究了交际代理之间自主合作的可能性,并介绍了一个名为角色扮演的新型合作代理框架。这个框架使用启示性提示,以确保与人类意图的一致性。在此研究基础上,我们进一步询问:是否可行使用交际代理来完成知识图谱的构建和推理任务?
在这个实验中,我们使用了CAMEL(Li等人,2023)中的角色扮演方法。如图6所示,AI助手被指定为顾问,AI用户被指定为知识图谱领域专家。在收到提示和指定的角色分配后,任务指定代理提供详细的描述以具体化概念。在此之后,AI助手和AI用户在多方设置中协作完成指定的任务,直到AI用户确认其完成。实验示例表明,使用多代理方法,与电影《绿皮书》相关的知识图谱被更有效、更全面地构建。这个结果也强调了基于LLM的代理在构建和完成知识图谱方面的优越性。

通过结合人工智能和人类专业知识的努力,AutoKG可以快速定制领域特定的知识图谱。该系统允许领域专家与机器学习模型进行交互,从而通过交换专家知识和经验,促进领域特定知识图谱的构建的协作环境。此外,AutoKG可以有效地利用人类专家的领域知识,生成高质量的知识图谱。同时,通过这种人机协作,它可以在处理领域特定任务时,提高大型语言模型的事实准确性。反过来,这个目标预计将增加模型的实用价值。
AutoKG不仅可以加快领域特定知识图谱的定制,而且还可以增强大规模模型的透明度和体现代理的交互。更准确地说,AutoKG有助于深入理解大型语言模型(LLMs)的内部知识结构和运作机制,从而提高模型的透明度。此外,AutoKG可以作为一个合作的人机交互平台,使人类和模型之间能够进行有效的交流和互动。这种互动促进了对模型学习和决策过程的更好理解和指导,从而提高了模型在处理复杂任务时的效率和准确性。尽管我们的方法带来了显著的进步,但它并非没有局限性,然而,这些局限性为进一步的探索和改进提供了机会:
API的使用受到最大Token限制的约束。目前,由于GPT-4 API不可用,正在使用的gpt-3.5-turbo受到最大token限制。这个约束影响了知识图谱的构建,因为如果超过了这个限制,任务可能无法正确执行。现在,AutoKG在促进有效的人机交互方面表现出缺点。在任务完全由机器自主进行的情况下,人类不能及时纠正交流过程中的错误发生。相反,在机器通信的每一步中都涉及到人类,可以显著增加时间和劳动成本。因此,确定人类介入的最佳时机对于知识图谱的高效和有效的构建至关重要。大型语言模型(LLMs)的训练数据是时间敏感的。未来的工作可能需要将来自互联网的检索特性纳入考虑,以弥补当前大型模型在获取最新或领域特定知识方面的不足。
4. 结论
在这篇论文中,我们初步调研了大型语言模型(LLMs),如GPT系列,在知识图谱(KG)构建和推理等任务上的表现。尽管这些模型在这些任务上表现优秀,我们提出了这样一个问题:LLMs在提取任务中的优势是源于它们庞大的知识库,还是源于它们强大的上下文学习能力?为了探索这个问题,我们设计了一个虚拟的知识提取任务,并为实验创建了相应的数据集。结果表明,大型模型确实具有强大的上下文学习能力。此外,我们提出了一种利用多个代理完成KG构建和推理任务的创新方法。这种策略不仅减轻了人工劳动,也弥补了各个领域人类专业知识的匮乏,从而提高了LLMs的表现。尽管这种方法仍有一些局限性,但它为LLMs的未来应用的进步提供了新的视角。
代充值")





网友评论