

先做个广告:如需代注册ChatGPT或充值 GPT5会员(plus),请添加站长微信:gptchongzhi
自动驾驶大模型到底该如何落地车端?
 推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
自动驾驶大模型是不是“越大越好”?
用大模型实现数据闭环,会不会成本更高?
自动驾驶大模型能带来哪些实际应用价值?
用大模型实现端到端自动驾驶,技术路线是否可行?
... ...
带着这些好奇和疑问
让我们从 ChatGPT 入手,完整了解
雪湖·海若的技术原理和产业价值吧!
Transformer 底层逻辑强力赋能
奇点时刻,是未来学家库兹韦尔提出的一个概念,是指机器智能达到并超过人类智能的那个时间点。库兹韦尔曾预测“技术奇点时刻将在2029年到来,届时机器智能将赶超人类水平。”
但现实进展往往超乎理论家的预期。随着 ChatGPT 横空出世,其优于绝大多数人类的语言表达和文本生成能力,让人们纷纷惊呼一个强人工智能时代的“奇点”来临,以至于众多 AI 科学家担心人工智能将会失控而给人类文明带来风险。

那么,这一切是如何发生的呢?让我们以风靡全球的大模型应用 ChatGPT 为例,来深入这场大模型带来的技术变革。
首先,ChatGPT 是一种基于 Transformer 架构和无监督预训练技术所产生的对话生成式模型,具有自然语言理解、文本生成、对话生成等功能,实质就是一个聊天机器人,可以实现智能语音助手、知识问答系统、各类文本的生成等功能。
ChatGPT 的底层技术是 OpenAI 推出的 GPT 自然语言模型。从2018年至今,OpenAI 一共推出了4代 GPT,而 ChatGPT 就是在 GPT-3 的升级版 GPT-3.5 的基础上,通过专门的微调、优化所做出来的用于自然语言对话的产品。
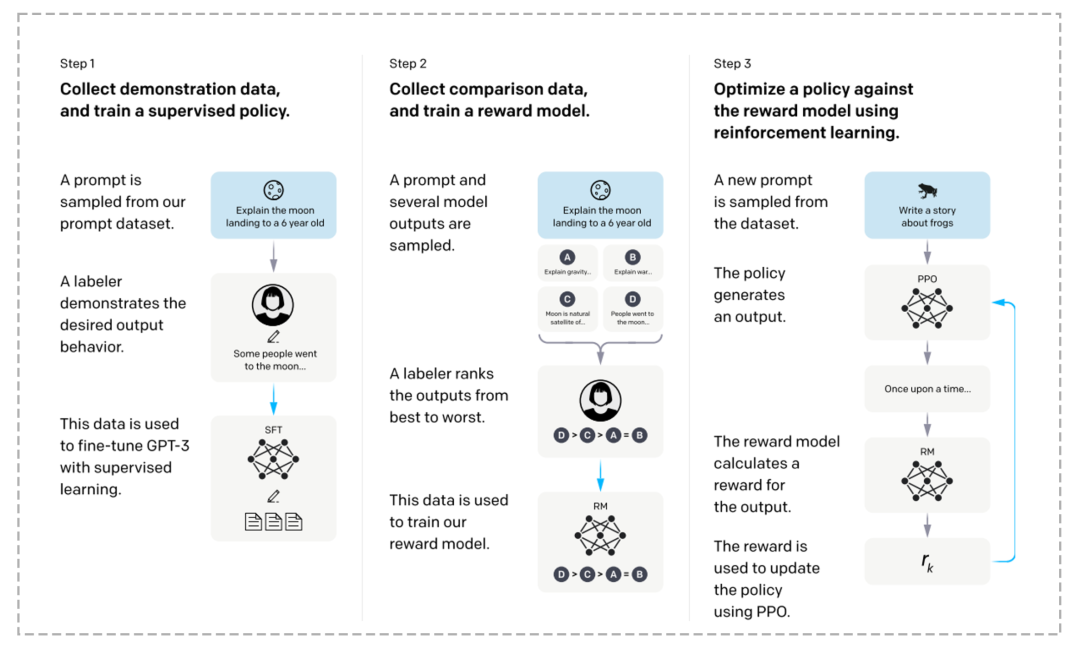
GPT 的基础结构是 Transformer,这是谷歌在2017年《Attention is all you need》论文中提出的一种模型架构,它是行业第一个完全依赖于自注意力机制(Self-attention)来计算其输入和输出表示的转换模型。 Transformer 架构的优点是能够处理任意长度的序列数据,这也是 Transformer 适用于自然语言处理当中长序列文本生成的关键。
第二,ChatGPT 采用了无监督预训练技术,可以自动地从大量无标注数据中学习到词汇、语法、语义等语言的规律和特征,从而提高模型的泛化能力和表现力,从而在后续的微调阶段中更加准确地预测和生成自然语言文本。
第三,微调(Fine-tune)是 ChatGPT 实现对话生成的关键技术之一,其原理是通过在有标注数据上进行有监督训练,从而使模型适应特定任务和场景。微调技术通常采用基于梯度下降的优化算法,不断地调整模型的权重和偏置,以最小化损失函数来提高模型的表现能力。简单来说,无监督预训练学习可以让模型学会的更多、更泛,而微调可以使得对具体问题的回答更专业、更准确。
第四,奖励模型(Reward Model)和人类反馈的强化学习(Human Feedback Reinforcement Learning)。奖励模型是通过人工标注的排序结果,训练出一种对应的奖励机制,用来预测用户更喜欢哪一个模型的输出结果。奖励模型又将用于训练强化学习(Reinforcement Learning)算法。在强化学习中,一个智能体通过与环境互动来学习,智能体通过观察环境的状态并根据奖励信号来采取行动,目标是最大化累积奖励。ChatGPT 在最后的阶段,就是利用基于人类偏好反馈的奖励模型,再用强化学习的方式进行训练,最终微调优化整个模型。
从最终的效果来看,与传统的对话系统相比,ChatGPT 可以自动地从大量的语言数据中学习到语言的规律和特征,从而实现更加自然、流畅的对话生成,可以完成像文本撰写、数学运算、翻译、代码生成等任务,甚至能胜任高质量论文撰写、以优异成绩完成大学专业考试等复杂语言任务。
ChatGPT 的惊人表现,使得生成式大模型技术迅速从幕后走向前台,并火速引爆全球大模型开发热潮。LLM 大模型出现带给行业很大启示,那就是通过对海量多模态数据的大规模无监督学习,借助“预训练+微调”的方式,就可以完成各种复杂的自然语言任务。
现在大模型正在从文本、语音、视觉等单一模态智能向跨场景、多任务的多模态方向演进,AI 大模型在跨领域内容学习和能力获取方面实现了质的飞跃。这使得几乎中美头部的互联网巨头和有一定能力的科技企业都在纷纷开展通用大模型的布局,而通用大模型也被认为将应用到金融、医疗、教育等各种垂直类行业,并展开商业化方向的探索。
现在,行业流传着这样一句话:以前所有的行业都可以用互联网的方式重做一遍,现在,所有的行业都可以用大模型重新做一遍。
毫末 DriveGPT 横空出世!
率先掀起自动驾驶行业变革
我们先来了解一下,自动驾驶为什么要用 AI 大模型的方式来进行实现呢?
自动驾驶是一个复杂的行动系统,包含了 AI 所需要的感知、认知推理、决策、控制和执行的所有环节,技术难度极高,因为涉及物理世界的风险,要求容错率极低,甚至要做到百分百的安全,对技术的能力边界要求会非常高。以传统深度学习小模型算法以及人工规则的方式难以突破完全自动驾驶要求的能力瓶颈,现在基于大模型方式对自动驾驶感知、认知算法进行训练和车端部署,将使得端到端自动驾驶的目标有可能实现,并且会逐步达到超过人类老司机水平的驾驶能力,最终实现无处不在的自动驾驶机器人,实现无处不在的机器智能移动。
那么,我们该如何在自动驾驶领域引入 AI 大模型呢?毫末率先在行业中进行了探索。

2023年1月,基于大规模真实量产数据驱动的数据智能体系,以国内最大的自动驾驶智算中心作为基础设施,毫末在对 Transformer 大模型前沿探索的基础上,率先同时推出了视觉自监督大模型、3D 重建大模型、多模态互监督大模型、动态环境大模型、人驾无监督认知大模型等五个自动驾驶大模型,成为行业首个将 GPT 大模型技术引用到自动驾驶认知决策当中的自动驾驶公司。

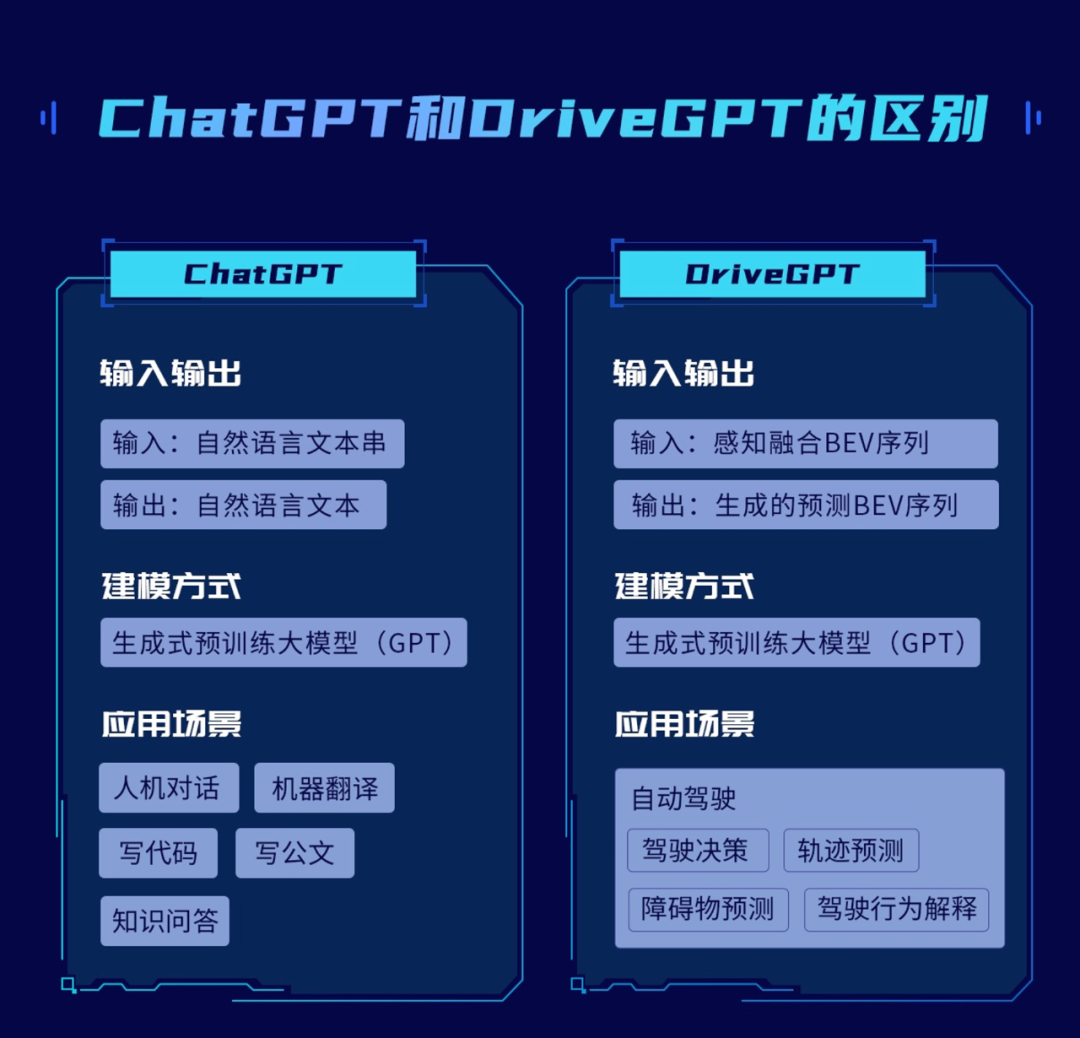
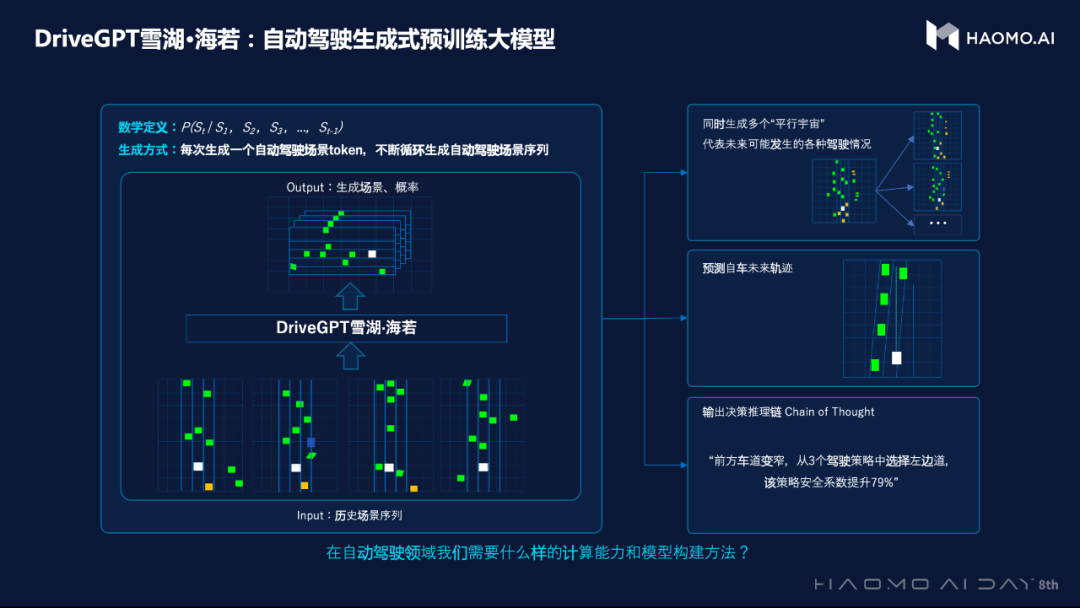
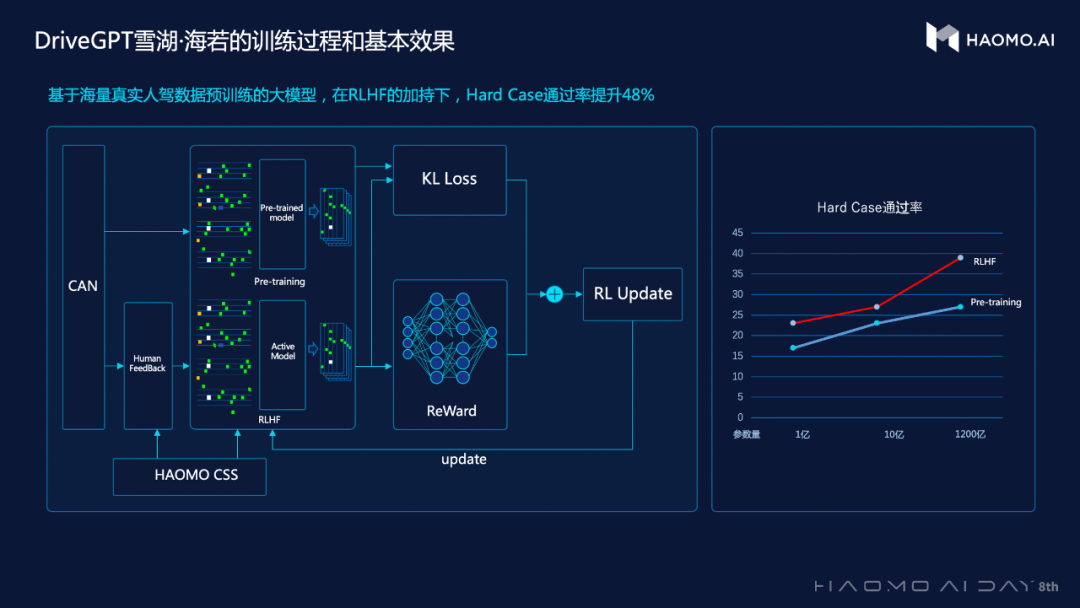

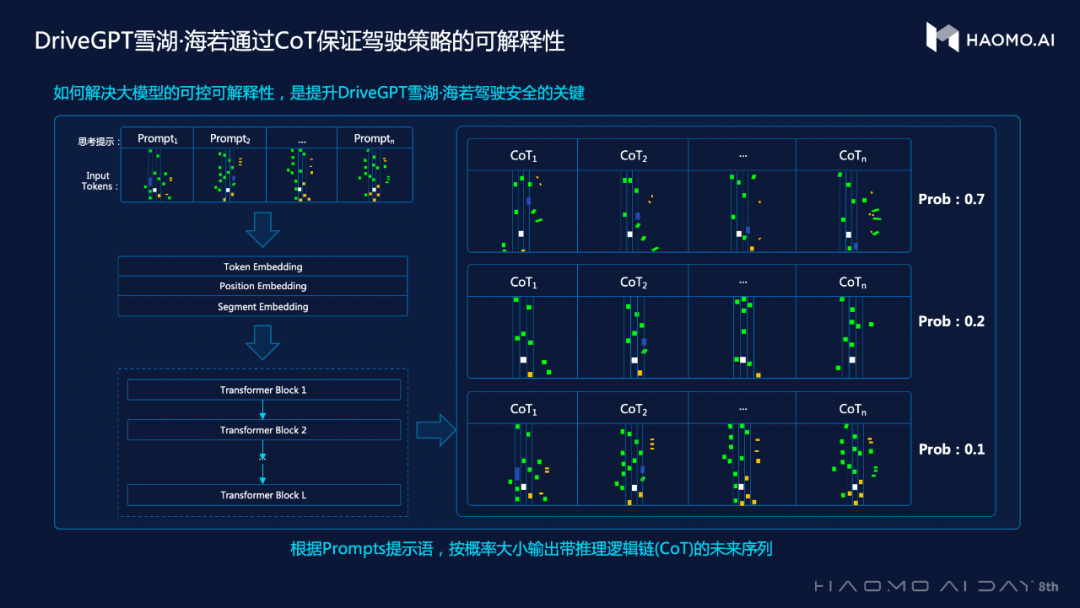


极致性能,一次拉满!
当之无愧的划时代全能选手
当前,毫末 DriveGPT 实现了模型架构与参数规模的升级,参数规模达到1200亿,预训练阶段引入4700多万公里量产车驾驶数据,RLHF 阶段引入5万段人工精选的困难场景接管 Clips。同时,毫末正在将感知能力融入到 DriveGPT 大模型训练当中,形成一整套的端到端自动驾驶能力模型。DriveGPT 也将具备道路驾驶场景的理解和识别、道路驾驶场景的重建与生成,以及智能驾驶辅助、驾驶能力测评等能力。
在驾驶场景理解能力上,DriveGPT 对视觉感知任务做了全面升级,以恢复真实世界的三维结构和纹理分布为目标,实现对道路驾驶环境的三维结构、速度场和纹理分布的融合训练,可适配所有主流视觉感知任务。目前,毫末视觉感知训练数据集达到400万 Clips,感知性能提升20%。同时,毫末也在中国率先开始验证使用鱼眼相机代替超声波雷达进行测距,以满足泊车要求。毫末把视觉 BEV 感知框架引入到了车端鱼眼相机,做到了在15米范围内达到30cm的测量精度,2米内精度高于10cm的视觉精度效果。如果在泊车场景使用纯视觉测距来取代超声波雷达,将进一步降低整体智驾成本。
在驾驶场景识别能力上,基于毫末 DriveGPT 所建立的 4D Clips 驾驶场景识别方案,可以使得单张图片的标注成本降到0.5元,是目前行业平均成本的1/10。毫末正在将图像帧及 4D Clips 自动驾驶场景识别服务向行业开放使用,这将大幅降低行业使用数据的成本,提高数据质量。
在场景重建和生成能力上,DriveGPT 可以支持单趟或多趟的纯视觉 NeRF 三维重建以及数据生成,从而可以构造大量自动驾驶的 Corner Cases,为行业提供更低成本、更大规模的自动驾驶能力测试的仿真环境,帮助行业伙伴快速提升自动驾驶技术能力。
在智能驾驶辅助能力上,DriveGPT 最终目标是实现端到端无人驾驶,分为感知和认知两阶段。当前的感知输出是 BEV 图,而认知则是把 BEV 感知结果作为输入进行驾驶决策训练。但是 BEV 感知结果会丢失很多信息,限制了驾驶决策的上限。而 DriveGPT 颠覆传统的感知逻辑,通过构建统一的空间计算 Backbone 实现通用视觉感知能力,在一个大模型中同时完成图片纹理、三维结构深度信息、实体语义信息、实体跟踪的学习,试图做到与人脑对物理世界的感知一样,实现通用的视觉感知能力。在认知阶段,将空间计算 Backbone 对接驾驶决策,采用更丰富、更全面的感知信息来训练驾驶决策模型,结合海量的真实驾驶数据训练,最终实现端到端自动驾驶甚至达到无人驾驶。
在驾驶评测能力上,如何提高自动驾驶系统的测试效率十分关键,传统的仿真不够真、路测成本又太高。借助 DriveGPT 的能力,可以在云端实现高效的驾驶能力测评。一方面,DriveGPT 本身的驾驶水平非常高,可以在云端通过大模型输出驾驶决策真值,来对比车端小模型的驾驶效果,实现大规模云端自动化测评,形成一种“Teacher-Student”模式。另一方面,由于 DriveGPT 具备很强的自主化能力,相当于一个独立智能体,通过在驾驶仿真场景中布置多个智能体,就可以模拟非常复杂的真实交通场景,尤其是针对复杂场景的多车交互与博弈,能给出更真实、更有效的测评结论。
当前,毫末将携手生态伙伴率先探索 DriveGPT 的四大应用能力,包括智能驾驶、驾驶场景识别、驾驶行为验证、困难场景脱困。DriveGPT 大模型可以将云端的能力对外开放,包括大规模数据的自动化标注、自动驾驶场景仿真测试等能力。
在清华大学讲席教授、智能产业研究院(AIR)院长张亚勤院士看来, ChatGPT 的横空出世,代表着人工智能正在进入以大模型为核心的数字3.0时代,大模型技术正在成为新技术革命下的新一代技术基础设施。
代充值")





网友评论