

先做个广告:如需代注册ChatGPT或充值 GPT5会员(plus),请添加站长微信:gptchongzhi
这是 OpenAI 的创始人之一 Andrej Karpthy 在微软 Build 2023 开发者大会上做的专题演讲《State of GPT》的一些笔记,主要是讲述了 GPT 是如何训练出来的。
 推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
通篇看完 GPT 的训练过程,给我的第一感觉是数据质量很重要,GPU数量也很重要,另外有大量的时间去迭代也很重要。后面将是大公司的游戏,创业公司很难参与进来。
但是我不理解的是,GPT依然是基于概率去生成文本的,为什么看起来就很智能了呢?Andrej Karpthy给出的答案是,GPT引入了人类的判断力,从而有了人的一部分智能。但是之前的算法模型也引入了人类标记的数据,这些人类标记的数据也带着人类的判断力,按理来说,也应该表现的有“智能”,然而在GPT之前,聊天机器人只能被称之为:人工智障。
或许就是所谓的大力出奇迹,数据量上去了,大模型就会表现出足够的智能了?
不过看完GPT的训练过程,我也理解了为什么GPT无法完成一个任务的拆分,但是对小任务完成的很好,例如它不能做到从零开始写一个斗地主游戏,但是它能很好的写出斗地主游戏里的每一个函数,这是它的训练方式所限制的。
最后的最后,GPT依然不会替代数学、物理这些充满逻辑性的学科,它究其根本还是一个搜索引擎,当然这已经足够开启下一次工业革命了。

这是GPT的训练流程,分为了四个步骤:预训练、有监督的微调、奖励建模、强化学习。花费时间最多和使用GPU数量最多的阶段是预训练,在每一个训练阶段都有相应的数据集去support。



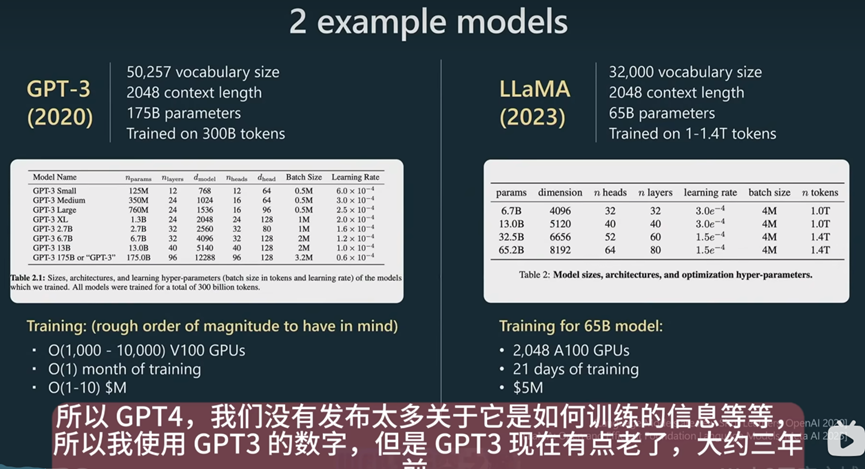
可惜没有GPT-4的信息,不知道它是如何做到的,毕竟GPT-4和GPT-3在准确率上差了可不少。



这张图非常有趣,它表示即使是从完全随机的权重开始(完全随机的输出结果),经过不断的迭代训练后,也能得到有意义的结果。
题外话:数学真是神奇啊。
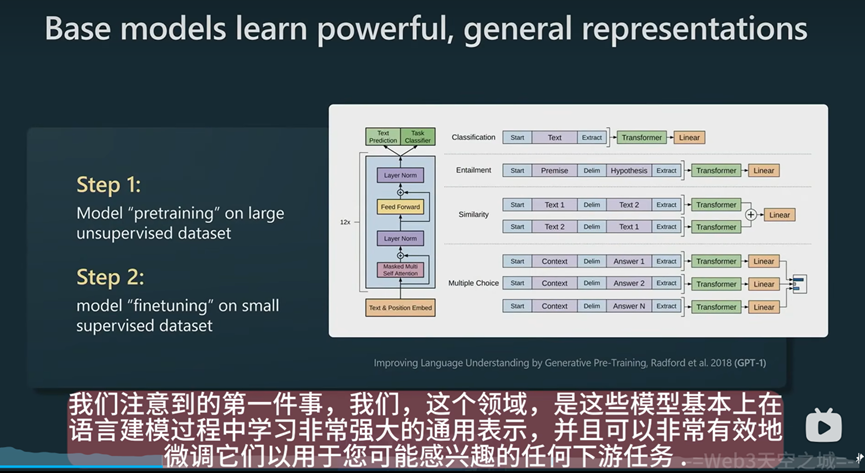

相比于之前要做一个基于文本信息的情感分类算法模型,需要专门进行标注数据,然后进行训练,有了大模型以后,就不需要专门标注数据,只需要对大模型进行预训练和transfomer,然后再通过几个例子进行微调就能获得很好的效果。
题外话:大模型一出,很多NLP领域没有意义了。毁灭你,与你无关啊。



使用提示词去训练模型比微调效果更好。
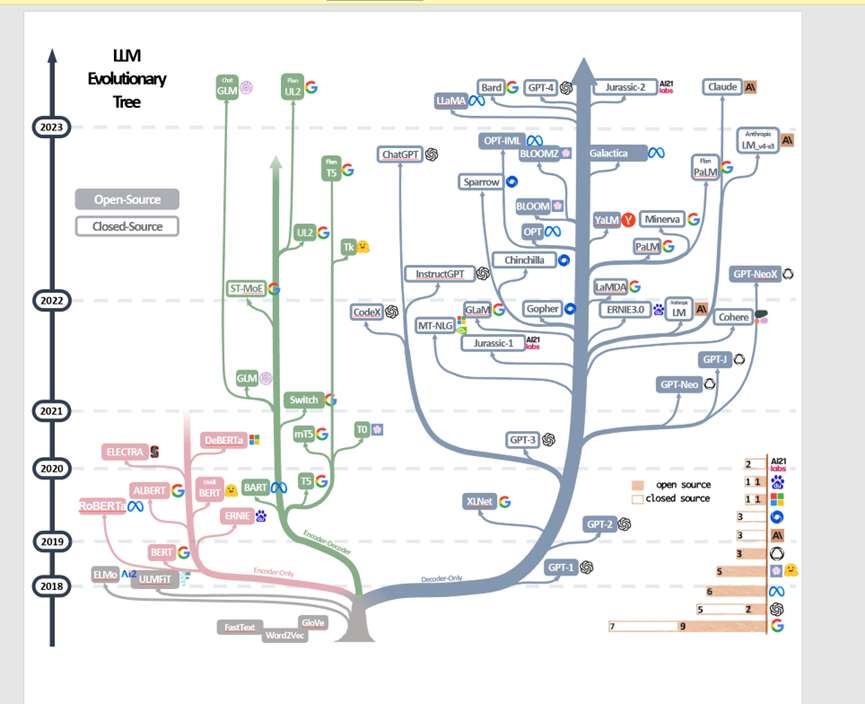
下面是一张很出名的大模型进化路线。谷歌和GPT从2018年开始选择了两条不同的路线,最终证明GPT的路线是正确的。


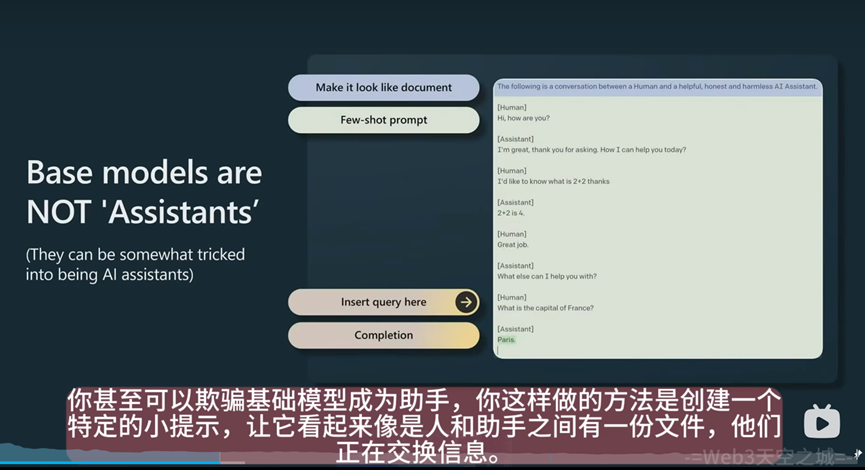
在完成基础模型之后,它还不是一个完整的人工智能助手,基础模型只能不断的根据你提供的句子去进行补全。所以需要提示词工程去让基础模型回答问题。


在这个阶段只需要少量的高质量数据,算法没有做任何改变,只是改变了一个训练集。也就是说,在预训练阶段可以不要求那么高质量的训练数据集,到了有监督的微调阶段就需要高质量数据集了。
接下来就是RLHF阶段了,包括奖励建模和强化学习两个阶段。


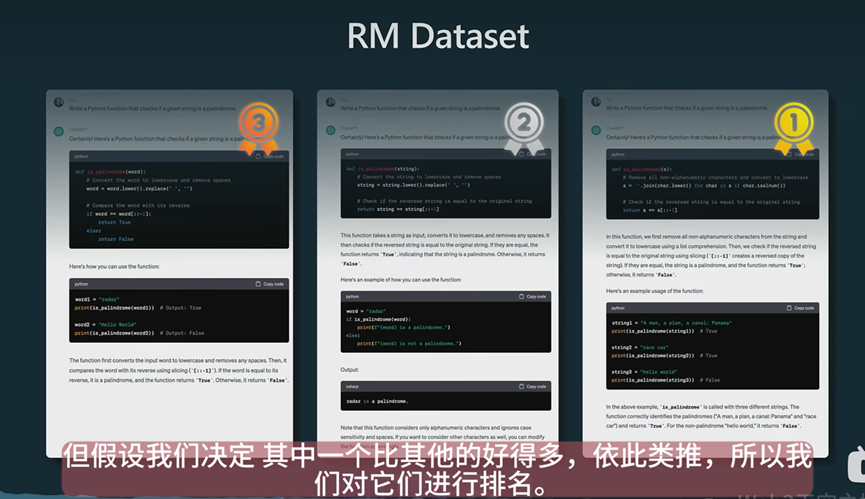


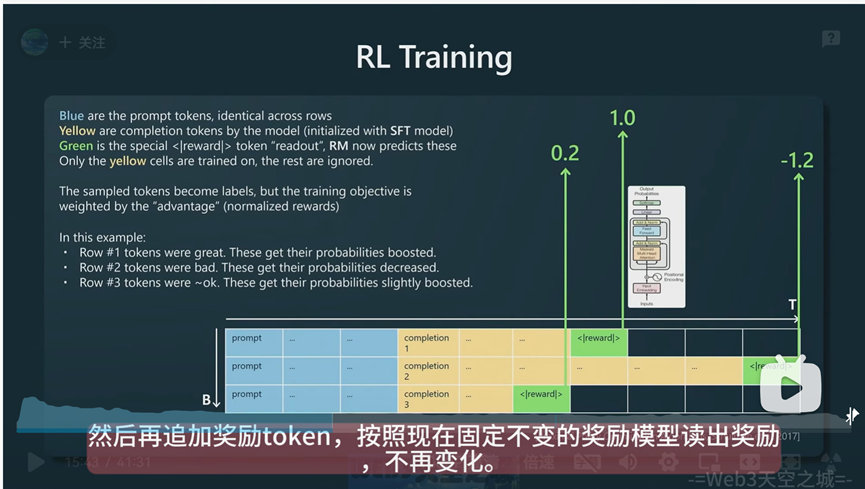

可以理解为奖励建模和强化学习就是人类给机器输出的结果打分,借助人类的判断力让机器学习。通过不断的提示和批次的迭代,从而让大模型获得一个好的输出结果。

基础模型就是完成预训练和有监督微调后的模型,SFT模型就是继续完成奖励建模阶段的模型,RLHF模型就是全部完成四个阶段,包括强化学习的模型
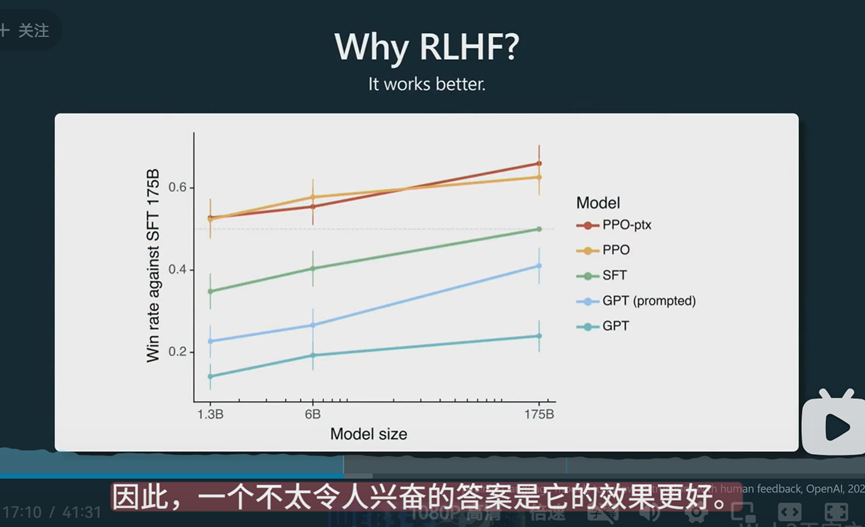
RLHF模型会比其它没有完整接受这四个阶段的模型效果要好。至于为什么要好,演讲者给出了他的猜测:
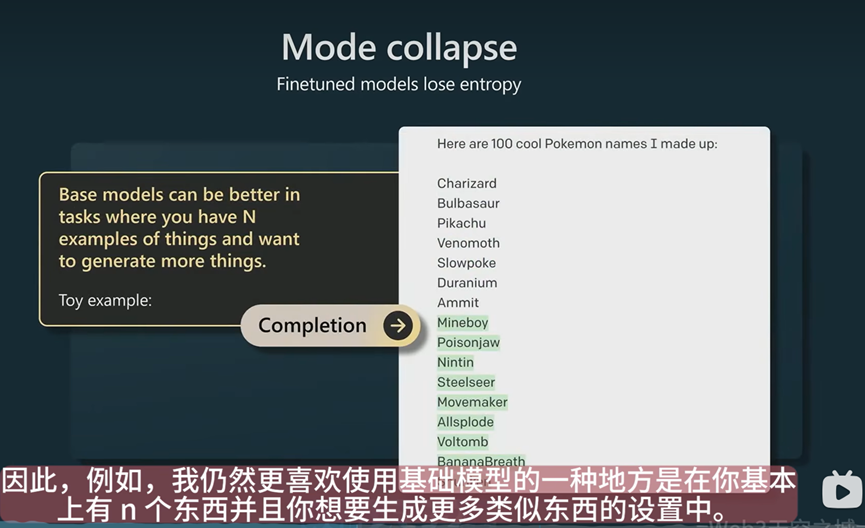
演讲者会更喜欢基础模型生成的东西,因为它的随机性更强,而经过奖励建模和强化学习后的模型,会丢失很多随机性(熵)。
最后是基础模型的排名:

代充值")





网友评论