

先做个广告:如需代注册ChatGPT或充值 GPT5会员(plus),请添加站长微信:gptchongzhi
本文的研主要究集中在8个实际的化学任务上,主要包括:1)名称预测,2)性质预测,3)产率预测,4)反应预测,5)逆转录合成(从产物中预测反应物),6)基于文本的分子设计,7)分子概括,8)试剂选择。本文分析借鉴了广泛可用的数据集,包括BBBP、Tox21、PubChem、USPTO、ChEBI等。通过精心选择的提示样本和特定提示,在零样本和少样本的情景学习中,对每个化学任务评估了三个GPT模型(GPT-4、GPT-3.5和Davinci-003)。
 推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
评估过程的工作流程如图1所示。生成、评估并选择合适的提示以转发到GPT模型。然后通过选定的指标对获得的答案进行定性和定量评估。
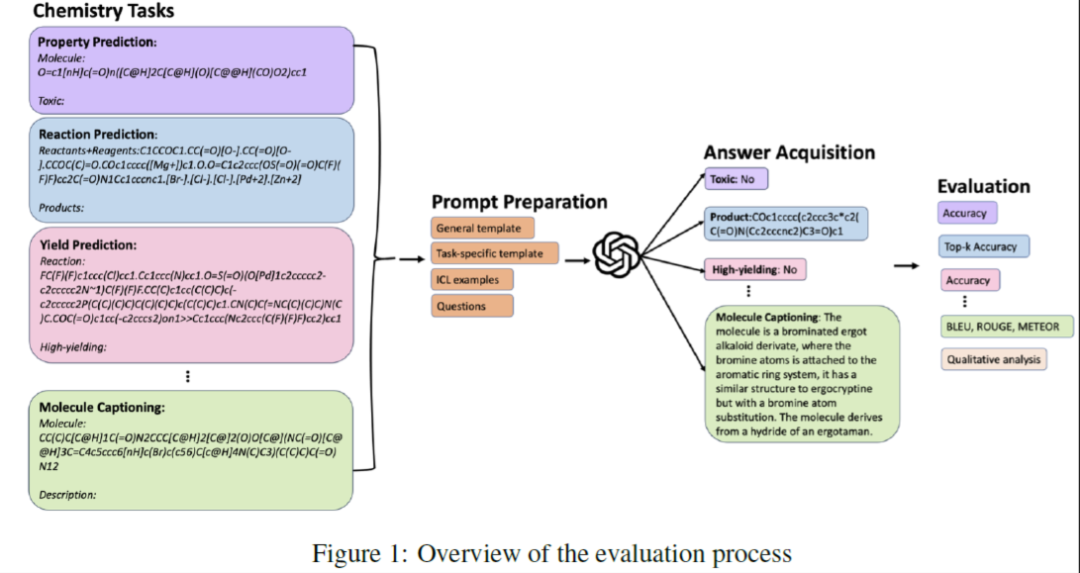
为了探索GPT模型在化学领域的能力,探究GPT在化学领域的三个基本能力:理解、推理和阐明解释。本文通过八项不同且广泛认可的实际化学任务来检查这些能力。
表2中从机器学习的角度根据任务类型、用于评估的数据集以及评估指标对这些任务进行了总结。
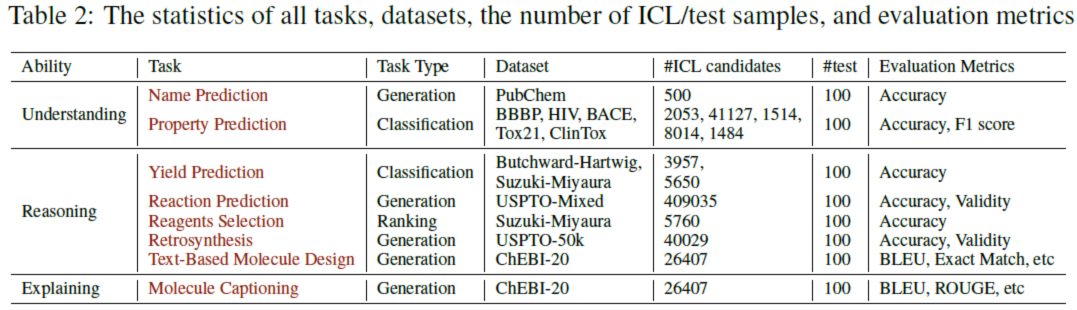
#ICL候选是指候选数据集的数量,本文从中随机或基于相似性搜索选择k个示范示例。这些候选集是经典机器学习模型中使用的分类或生成模型的训练集。本文设置了100个实例的测试集,从原始测试数据集中随机采样(与训练集不重叠)。为了减少LLM随机性对结果的影响,每个评估实验重复五次,并报告平均值和方差。
零样本提示
对于每个任务,应用一个标准化的零样本提示模板。如图2所示,指示GPT模型以化学家的身份发挥作用。框架内的内容针对每项任务进行定制,以适应其特定的输入和输出。GPT模型的响应仅限于返回所需的输出。

ICL是GPT模型的一种使用方式,其预测是基于提供的示例 。本文特别将ICL定义为一种少样本的情景学习方法。为了全面检查GPT模型在每个特定化学任务中的能力,设计了一个特定任务的ICL提示模板。如图3所示。
将模板分为四个部分:
General template:与零样本提示几乎相同,指示GPT模型扮演化学家的角色,并指定具有相应输入和输出的化学任务.
Task SpecificTemplate:考虑到化学相关任务的响应必须准确且化学合理,需要阻止GPT模型产生其他不相关的信息。为此,引入了{Task SpecificTemplate},它由三个模块组成:[输入解释]、[输出解释]和[输出限制],专门用于减少不需要的信息。这些模块的内容需要针对每项任务重新定义。
ICL: 样本示例是直接上下文连接的,[Input]和[Output]分别表示每个任务的输入和输出的特定名称,[Input_content]和[Output_content]分别表示每个任务的输入和输出的数据。例如,在反应预测任务中,[Input]是"反应物+试剂",[Input _content]是反应物和试剂的实际SMILES。[Output]是"产物",[Output_content]是产物的smiles。每个任务的详细ICL提示将在下面各自的章节中介绍。具体结构如下:
[Input]: [Input_content]
[Output]: [Output_content]
...
[Input]: [Input_content]
[Output]: [Output_content]
Question: 最后Question部分介绍了GPT模型的测试用例。

为了研究ICL示例的质量和数量对每项任务绩效的影响,本文探索了两种ICL策略。
本文通过两种策略进行实例选择:{Random, Scaffold}。在随机策略中,从ICL候选池中随机选择k个示例。在Scaffold策略中,如果[Input_content]是一个分子SMILES,使用半径为2的Morgan Fingerprint通过计算Tanimoto Similarity来计算分子骨架的相似性,再选择前k个相似的分子SMILES。如果[Input_content]是一个描述字符串,如IUPAC名称或其他名称,使用Python内置的difflib.SequenceMatchertool来选择前k个类似的字符串。
为了探索ICL示例数量对性能的影响,还在每个任务中对ICL示例的数量k进行变化。
对于一个分子,有不同种类的化学名称,如SMILES、IUPAC名称和分子式。为了研究GPT模型是否具有基本的化学名称理解能力,构建了4个化学名称预测任务,包括:smiles2iupac、iupac2smiles、smiles2formula和formula2smile。从PubChem中收集了630个分子及其相应的名称,包括SMILES、IUPAC名称和分子式。随机抽取500个分子作为ICL候选,30个分子作为验证集,100个分子作为测试集。对于所有的名称转换任务,使用精确匹配的准确性作为评估性能的指标。
smiles2iupac预测的一个示例如图4所示。对于其他名称转换任务,只更改代表不同任务的下划线部分及其相应的输入名称和输出名称。

结果
结果如表3所示(只报告了具有代表性的方法及其通过验证集上的网格搜索进行的最佳提示设置)。在所有四个名称预测任务中,最佳方法的准确度都极低(在iupac2smiles任务中为0.014,在smiles2formula任务中为0.086),甚至为0(在smiles2iupac和formula2smile任务中)。这表明GPT模型缺乏基本的化学名称理解能力。Davinci-003的精度明显低于其他型号 。

分子性质预测是计算化学中的一项基础任务,由于其在药物发现、材料科学和化学其他领域的潜力,近年来受到了极大的关注。该任务涉及使用机器学习技术根据给定分子的分子结构预测其物化性质。目的是进一步探索LLM在分子性质预测中的潜力,并在一组基准数据集上评估其性能,如BBBP、HIV、BACE、Tox21和ClinTox,这些数据集最初由引入。这些数据集由大量SMILES集合组成,并与突出所评估特定特性的二元标签配对,如BBBP:血脑屏障渗透性,HIV:抑制HIV复制,BACE:一组人类β分泌抑制剂的结合结果,Tox21:化合物的毒性和ClinTox:药物因毒性原因未通过临床试验。对这些数据集的全面解释可以在[53]进行的原始研究中参考。
对于ICL,要么随机选择k个样本,或者使用RDKit通过计算TanimotoSimilarity[28]选择前k个最相似的分子。然而,重要的是,使用后一种方法并不能确保类之间的均匀分布。在的研究中,对两类数据集采用了策略抽样方法:平衡数据集和高度不平衡数据集。对于平衡数据集,如BBBP和BACE,从原始数据集中随机选择30个样本进行验证过程,并选择100个样本进行测试。相反,对于表现出显著标签失衡的数据集(39684: 1443 ≈ 28: 1,以HIV数据集为例),从大多数和少数类别中选择样本,以达到4:1的比例。这种战略方法使能够为评估过程保留一个具有代表性的样本,尽管数据集中最初存在高度不平衡。为了评估结果,由于类别不平衡,使用分类准确性以及F1score作为评估指标。以MoIR[47], PDF为基线,这是一个基于图神经网络的模型,以分子图为输入,并将其性质预测为二元分类问题。
少样本提示学习
图5展示了用于属性预测的ICL提示的示例。在任务特定模板中,详细解释了预测血液屏障穿透的任务,以帮助GPT模型理解BBBP数据集的输入SMILES。此外,为输出建立了一定的约束条件,以符合属性预测任务的特定特征。

结果
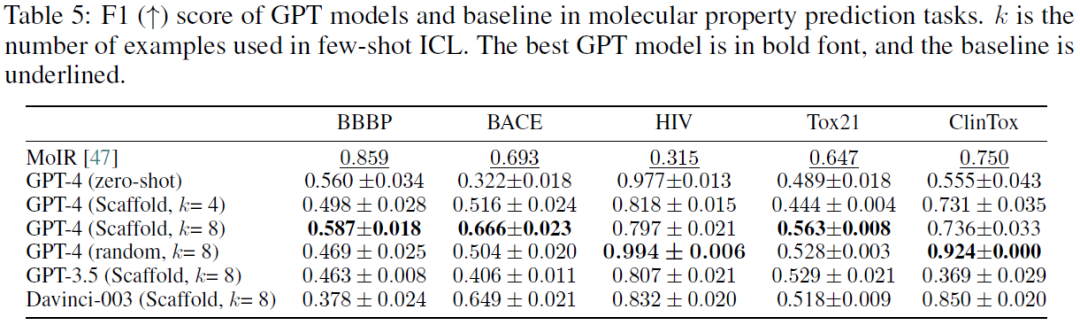
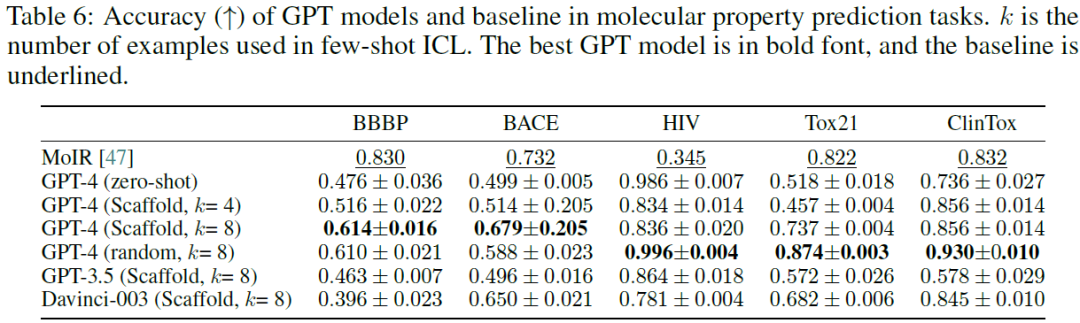
结果在表5中以F1表示,准确度在表6中。观察到,在4/5 (2/5)的数据集上,GPT模型在F1方面优于基线模型。在所检查的GPT-4模型范围内,GPT-4在预测分子性质方面超过了Davinci-003和GPT-3.5。在的研究中,发现有样本的情景学习(ICL)会显著提高模型性能。这表明ICL的数据量与模型的预测精度之间的直接关系。同时,的研究提供了经验证据,证明基于scaffold相似性筛选的性能在三个不同的数据集(BBBP、BACE、Tox21)上超过了随机采样的性能。对此的一个合理解释可能是样本骨架分子和查询分子之间的结构具有一定的相似,这可能会使GPT模型偏向于更准确的决策。
少样本提示学习
用Butchward Hartwig数据集的一个例子展示了的ICL产量预测提示。如图6所示,结合了一个输入解释(其中反应器用“.”分隔,产品用“>>”分隔)来帮助大型语言模型。此外,还强制执行输出限制,以确保生成有效的结果。

结果
结果如表7所示。的分析表明,在产量预测任务中,GPT模型的表现低于已建立的基线模型UAGNN。然而,值得注意的是,UAGNN模型是在包括数千个例子的完整训练数据集上训练的。相对于其三个模型,GPT-4是具有更优的性能,在预测反应产率方面盖过了Davinci-003和GPT-3.5。在的研究过程中,发现了ICL可以提高模型性能。这表明ICL数据的数量与所考虑的模型的预测准确性之间存在固有的相关性。这种现象在GPT-4的情况下尤为明显,当ICL实例的数量从4个增加到8个时,观察到性能的显著改善,无论是在Butchward-Hartwig还是Suzukicoupling反应中。这表明,即使在相同的模型架构中,提示示例的数据的数量也会显著影响预测能力。

反应预测是化学领域的一项核心任务,对药物发现、材料科学和新合成路线的开发具有重要意义。给定一组反应物,本任务的目标是预测化学反应过程中最可能形成的产物。在本任务中,使用广泛采用的USPTO-MIT数据集来评估GPT模型的性能。该数据集包含从美国专利中提取的约470000个化学反应。在实验中,使用USPTO混合数据集,其中反应物和试剂字符串由“.”分隔。从原始验证集随机抽取30个样本进行验证,从原始测试集随机抽取100个样本进行测试。使用Top-1精度作为评估指标,Chemformer, PDF作为基线,因为它在反应预测的机器学习解决方案中具有优异的性能。Chemformer是一个seq2seq模型,用于在给定反应物和试剂作为输入时预测输出产物。还报告了每种方法生成的无效SMILES的百分比。
少样本提示学习
用于反应预测的ICL提示的一个示例如图7所示。鉴于反应预测任务的性质和USPTO-MIT数据集的特征,在任务特定模板中添加输入解释(说明输入包括用“.”分隔的反应物和试剂),以帮助GPT模型理解输入SMILES。此外,结合了输出限制来指导GPT模型生成化学有效和合理的产品。

结果
结果如表8所示。可以观察到,与基线相比,GPT模型的性能显著较差,尤其是对于零样本提示(Top-1Accuracy仅为0.004,它产生17.4%的无效SMILES)。GPT模型的竞争性较差的结果可归因于对代表反应物和产物的SMILES串以及将反应物转化为产物的反应过程缺乏深入了解。同样值得一提的是,Chemformer获得的高精度是由于它在完整的数据集上进行了训练。第11节讨论中总结了更多结论和详细分析。

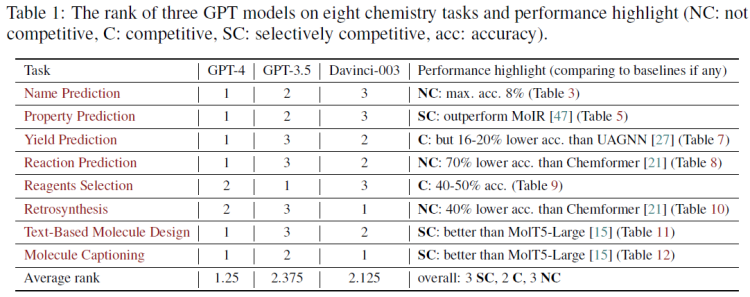
在所评估的三个模型中,GPT-4的综合性能优于其他两个模型。三个模型在8项任务上的排名如表1所示;
GPT模型在要求精确理解分子SMILES表示的任务中表现出较差的性能,如名称预测、反应预测和逆合成
GPT模型在与文本相关的解释任务(如分子概括性解释)中表现出强大的能力;
对于可以转换为分类任务的化学问题,如化合物性质预测和产量预测,与使用经典机器学习(ML)模型作为分类器的基线相比,GPT模型可以实现有竞争力的性能,甚至更好,如表1所示。
参考文献:
Guo, T., et al. (2023). "What indeed can GPT models do in chemistry? A comprehensive benchmark on eight tasks." arXiv preprint arXiv:2305.18365.
点击下方名片,回复GPT查看原文
代充值")





网友评论